

Женило Валерий Романович, доктор технических наук
УДАЛЕНИЕ ИЗ РЕЧЕВОГО СИГНАЛА СЛЕДОВ ИНЫХ ФОНООБЪЕКТОВ ПУТЕМ РАЗЛОЖЕНИЯ ИХ НА МИКРОВОЛНОВЫЕ ЭЛЕМЕНТЫ
Источник: журнал "Специальная Техника"
Удаление из речевого сигнала следов иных фонообъектов, мешающих правильному восприятию речи или снижающих качество ее звучания, – достаточно актуальная задача. К сожалению, для ее решения многие методы фильтрации, в том числе и адаптивные, иногда оказываются недостаточно эффективными. Особо остро этот вопрос стоит в криминалистике, требующей сохранения аутентичности следов исследуемых фонообъектов на всех этапах исследования и, в частности, на этапе очистки речевого сигнала от шумов и помех.
В настоящее время системы фильтрации речевых сигналов, доступные экспертам-криминалистам, обладают одним весьма негативным свойством. Все они, так или иначе, искажают следы фонообъектов, по которым эксперт в последующем принимает решение по тому или иному вопросу экспертизы.
В этой связи в Экспертно-криминалистическом центре МВД России были проведены специальные исследования (И.Н.Тимофеев, Т.И.Голощапова, И.В.Докучаев. Возможности использования средств многоканальной шумоочистки сигнала при проведении идентификационных исследований: Тезисы докладов Международной конференции "Информатизация правоохранительных систем", М., 1997. С. 194 - 196.) по определению того, какие системы фильтрации сигналов для повышения разборчивости речи могут использоваться для очистки следов речи от шумов, помех и наслоений следов иных фонообъектов, а какие – нет. Оказалось, что практически все имеющиеся системы фильтрации речевых сигналов смещают (искажают) те акустические параметры речевых сигналов, по которым принимаются решения о тождестве следов голоса и артикуляции говорящего, о диагностике и идентификации условий звукозаписи и т.п. Это происходит потому, что изначально цель любых подобных автоматических систем заключается в повышении разборчивости речи, воспринимаемой на слух, любым путем вплоть до искажения самого речевого сигнала, делающего его совершенно непохожим на натуральный (природный) речевой сигнал.
Бесспорно, задача повышения разборчивости речевых сигналов так же сложна, как и любая другая в речевой технологии. Поэтому разработчики названных систем вынуждены идти на определенные жертвы качества получаемого очищенного речевого сигнала. Живой речевой сигнал есть след интеллектуального фонообъекта в реальных земных условиях - со всеми эффектами отражения волн, реверберации, детонации магнитофонов и т.п. Описать такой след математически с достаточной степенью достоверности априори очень сложно. Поэтому-то разработчики систем повышения разборчивости пренебрегают возможными изменениями ряда качественно важных характеристик отфильтрованного речевого сигнала ради решения главного вопроса - что сказано в условиях помех или шумов.
На практике чаще всего складывается следующая ситуация: чтобы измерить параметры речевых сигналов для проведения идентификационных исследований, требуется предварительно очистить сигналы от помех и шумов, но после этой процедуры проведение идентификационных исследований по очищенным следам речевых сигналов зачастую становится просто недопустимым.
Чтобы хоть как-то сдвинуть решение этой проблемы с мертвой точки, следует, по мнению автора, включать в саму систему очистки речевых сигналов интеллект эксперта, а не оставлять за автоматической системой обработки сигналов право самой “решать” – что важно оставить в речевом сигнале, а что можно удалить. Такой подход поначалу будет весьма непопулярным, поскольку производительность “труда” автоматических компьютерных систем в вычислительной части несравнимо выше производительности труда человека. Однако следует помнить, что настолько же разнится, но в другую сторону производительность их труда в интеллектуальной части.
Все первые технологии человеко-машинных систем фильтрации сигналов будут иметь низкую производительность. Однако по мере их развития и типизации они, несомненно, будут ускоряться за счет передачи компьютеру всех заведомо трудоемких вычислительных процессов.
Ниже предлагается один из подходов создания подобной технологии. Он основан на расслоении всех следов фонообъектов, присутствующих в заданном сигнале, на две группы с последующим восстановлением двух сигналов во временной области таким образом, чтобы каждый из них содержал следы лишь одной группы и, что самое главное, оставался аутентичным.
Следует отметить, что в фоноскопии этот подход возможен потому, что до этапа преобразования акустической волны в электрическую (в микрофоне) все акустические сигналы ведут себя как обычные волны со всеми вытекающими отсюда свойствами, преимуществами и недостатками. Поэтому, если, например, в дактилоскопии наложение нового отпечатка пальца, покрытого краской, на старый может полностью закрыть отдельные элементы последнего, то в фоноскопии наложение двух акустических волн (речевых сигналов) приводит к их интерференции. В фоноскопии, если следы нескольких фонообъектов смешиваются, то они “живут” независимо друг от друга, не разрушая один другого, а лишь интерферируя. Наложение одного следа на другой не уничтожает последний так, как это происходит при наложении нескольких отпечатков пальцев.
В работе “Компьютерная фоноскопия” (1995) автором была предложена классификация основных типов фонообъектов, чаще всего встречающихся в криминалистической практике. Их немного: человек, магнитофон (или обобщенно - регистратор речи), гармоника, голос, серия однотипных импульсов, прочие. При небольшом числе элементов классификации за каждым из них стоит сложная специфическая система математического описания их свойств. Каждому из этих типов фонообъектов соответствует своя технология их анализа, обработки или очистки. Проще всего такую технологию создать для фонообъектов типа гармоники. Однако поскольку таковые в чистом виде на практике встречается относительно редко, постольку и разработка соответствующих технологий менее актуальна, чем, например, разработка технологий для фонообъекта типа “человек”. Поэтому целесообразно начать с реализации технологии анализа и обработки следов фонообъектов типа “прочие”, прежде всего по критерию “отношение затрат на разработку - к практической актуальности”. Однако если в научных подразделениях системы МВД число разработчиков фоноскопических систем будет расти, то в ближайшее время можно ожидать решения аналогичного вопроса применительно и к остальным типам фонообъектов.
Разработать технологию разделения следов разных фонообъектов, относящихся к категории “прочие”, полезнее еще и потому, что фактически эта технология должна быть предельно универсальной, в силу чего, вероятнее всего, в некоторых случаях сможет помочь разделять следы и упомянутых выше типов фонообъектов. Конечно, при своей универсальности она может стать технологически менее эффективной, но, повторяем, это позволит сдвинуть с мертвой точки решение принципиально сложного для криминалистики вопроса.
Категория фонообъекта “прочие” предполагает, что реальные свойства этого фонообъекта неизвестны. Следовательно, математического описания его свойств нет, а поэтому, пожалуй, единственно приемлемым в настоящее время математическим аппаратом представления и анализа следов этих фонообъектов является классическое спектральное описание на основе преобразования Фурье.
Поскольку базовыми функциями преобразования Фурье являются гармоники, то ясно, что наиболее адекватной предлагаемая технология окажется для тех сигналов, у которых основными информационными элементами являются гармонические компоненты. Таковыми фактически являются все тональные участки речевых сигналов.
Представление следов фонообъекта с помощью традиционных сонограмм позволяет эксперту визуально различать отдельные частотно-временные компоненты даже нескольких смешанных сигналов - следов разных фонообъектов. Напомним, что сделать то же самое во временной области с помощью исходной осциллограммы практически невозможно.
Для удобства дальнейшего описания введем несколько вспомогательных определений.
Построение сонограмм имеет множество степеней свободы. Поскольку сонограмма - это фактически последовательный ряд амплитудных спектров, следующих друг за другом с постоянным шагом во времени, то будем говорить о ней как о фильме, состоящем из множества кадров. Всякий такой фильм описывается двумя основными параметрами: частотой кадров и разрешающей способностью каждого кадра. Но если в кинофильмах связь между этими параметрами обычно не задается, то в фоноскопии она имеется. Суть такой связи заключается в следующем. Предположим, что спектры для построения сонограммы рассчитываются с помощью временного окна Гаусса, обеспечивающего разрешающую способность по частоте равной величине sf Гц. В этом случае строить фильм с частотой большей, чем 2psf кадров в секунду не имеет смысла в силу возникновения информационной избыточности смежных спектров или, как мы их еще будем называть, кадров фильма сонограммы (далее для краткости фильм сонограммы будем просто называть сонофильмом).
Если придерживаться оптимального соотношения частоты кадров и их разрешающей способности, то получается, что задание сонофильма имеет всего лишь одну степень свободы. Это может быть или частота кадров, или разрешающая способность отдельного кадра. Предположим, что в качестве степени свободы построения сонофильма была выбрана частота кадров. Какой она должна быть?
Выбор частоты кадров сонофильма зависит от свойств визуализируемого сигнала или иначе – свойств исследуемого фонообъекта. Если это летучие мыши или дельфины, то частота сонофильма должна быть относительно высокой. Если это периодические звуки морских волн или иных медленно текущих процессов (сигналы электрокардиограммы, дыхания и т.п.), то частота сонофильма будет относительно мала. Для разных механизмов, издающих сигналы, имеющие периодическую форму, частота кадров сонофильмов, наиболее четко отражающих их свойства, будет разная.
Какой должна быть частота сонофильма речевого сигнала человека пока еще точно не установлено. Очень может быть, что она будет близка к минимальной частоте обычного кинофильма, при которой мелькания кадров еще не видно, но если фильм просматривать с более низкой частотой, то мелькания становятся заметными. Для изложенных ниже результатов автором эмпирически выбрана частота построения сонофильма равная 150-ти кадрам в секунду. Объективности ради следует отметить, что для решения этого вопроса необходимо провести специальные исследования оптимальной частоты построения сонофильма. Критерий оптимальности будет зависеть от решаемой задачи. Им может быть, например, мера отличия исходного речевого сигнала от синтезированного по всем следам того же самого речевого сигнала, отраженным на сонофильме.
Говоря об отражении следе фонообъекта с неизвестными свойствами на сонофильме, следует учитывать, что его природа может быть совершенно произвольной - импульс, ряд отдельных гармонических компонентов, серия импульсов, превращающаяся (или нет) в голос, и т.п. Во всех этих случаях их математическое описание будет различным. Выбор базового описания фактически определяется типом преобразования исходного сигнала из осциллографической формы в сонографическую. Поэтому если сонофильм строится с помощью преобразования Фурье и временного окна Гаусса, то и базовые элементы, на которые будут разлагаться следы фонообъектов, должны принадлежать той же категории. В этом случае отражение простейшего элемента следа фонообъекта на сонофильме будем представлять в следующем виде:
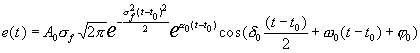 , (1)
, (1)
где
sf – разрешающая способность спектров по частоте;
t0 – положение окна Гаусса во времени (фактически это время текущего кадра сонофильма);
w0 – частотная гармоническая компонента следа фонообъекта в текущем кадре;
j0 – начальная фаза гармонической компоненты следа фонообъекта в текущем кадре;
a0 – скорость изменения амплитуды гармонической компоненты следа фонообъекта в текущем кадре;
d0 – скорость изменения частоты гармонической компоненты следа фонообъекта в текущем кадре;
A0 – амплитуда гармонической компоненты следа фонообъекта в текущем кадре.
Разложение исходного речевого сигнала на ряд микроволновых элементов (1) в каждом кадре сонофильма фактически осуществляется при расчете любой традиционной амплитудной сонограммы.
Элементарная гармоническая компонента сигнала, представленная по формуле (1), по некоторым свойствам напоминает популярное в настоящее время в речевых информационных технологиях понятие “вейвлет”. Например, как и вейвлет, функция e(t) очень быстро стремится к нулю при отклонении t от t0 более чем на несколько sf.
В текущем кадре каждая элементарная гармоническая компонента следа фонообъекта априори неизвестного нам типа может иметь пять степеней свободы: A0, w0, j0, a0 и d0. Если этот компонент относительно достаточно мощен, то все его параметры можно вычислить с достаточной степенью точности по одному мгновенному кадру комплексного спектра.
Последнее утверждение весьма существенно отличает технологию работы с фонообъектом неизвестной природы (фонообъекты “прочей” группы) с фонообъектами определенной группы. Если мы имеем дело с фонообъектами определенной группы, то динамику его следа можно моделировать и предсказывать на относительно большом промежутке времени. В этих случаях в отдельных кадрах сонофильма может происходить полное исчезновение следа интересующего нас фонообъекта в следах более мощных фонообъектов. Однако благодаря интерференции следов разных фонообъектов теоретически возможно их расслоение.
При работе с фонообъектами “прочей” группы нельзя надеяться на то, что в интерференционной картине эксперт сможет явно выделить следы нужного или ненужного фонообъекта. Поэтому реально следы можно корректно разделить лишь при условии, что след одного из фонообъектов существенно более мощный, чем след другого. В этом случае при оценке параметров микроволновых элементов (1) следа самого мощного фонообъекта в кадре сонофильма интерференционными явлениями можно пренебречь.
Для проверки технологической состоятельности высказанных гипотез были проведены следующие эксперименты.
Эксперимент 1. Проверка качества разложения речевого сигнала на микроволновые элементы (1) в каждом кадре сонофильма. На рис. 1 в верхней его части показана динамика уровня мощности экспериментального речевого сигнала, а в нижней – соответствующий сонофильм.
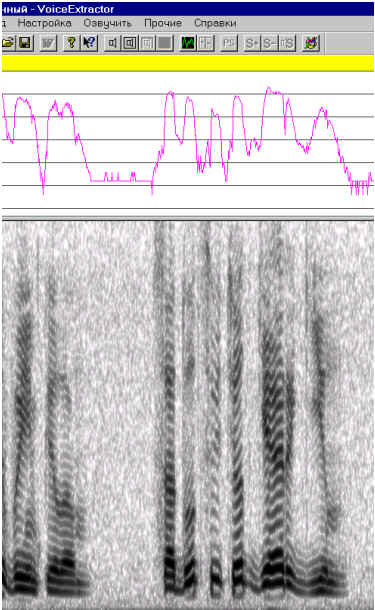
Рис. 1. Уровень мощности и сонофильм исходного речевого сигнала.
Из условий эксперимента предполагается, что все следы во всех кадрах полученного сонофильма следует включить в дальнейший анализ. Поэтому все следы на сонофильме разлагаются на микроволновые элементы (1). Затем из этих микроволновых элементов был собран новый речевое сигнал. Результат этой сборки показан на рис. 2. Анализ собранного таким образом синтетического речевого сигнала показал следующее.
На слух синтетический сигнал практически не отличается от оригинала. В нем не появляются какие-либо призвуки, “металл” или иная неестественная синтетичность.
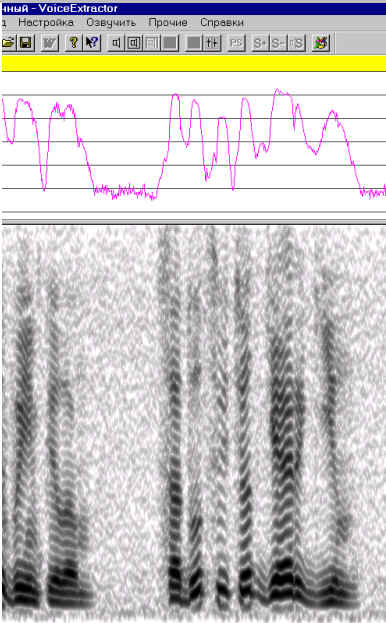
Рис. 2. Уровень мощности и сонофильм речевого сигнала, синтезированного по всем следам, отраженным на сонофильме на рис.1
По динамике уровня мощности и сонофильму синтезированного сигнала видно (рис. 2), что от оригинального речевого сигнала синтетический отличается рисунком шумов, сопутствующим речевому сигналу, который хорошо просматривается в речевых паузах.
Наибольшие отличия наблюдаются в области нулевой частоты и частоты Найквиста. Это объясняется тем, что оценить микроволновые составные компоненты исходного сигнала с достаточной точностью в указанных областях невозможно. Поэтому для анализа и синтеза они оказываются потерянными. Но в действительности это небольшая потеря, поскольку, например, в данном случае оказались потерянными частотные компоненты от нуля до 25 Гц. Эти потери слухом не воспринимаются. Потери в такой же узкой полосе частот шириной 25 Гц, но около частоты Найквиста, тоже нельзя назвать таковыми в строгом смысле слова, поскольку в процессе аналого-цифрового преобразования (АЦП) следов фонообъекта все их частотные компоненты, лежащие вблизи частоты Найквиста, всегда удаляются (например, входными фильтрами АЦП).
Сравнение осциллографической формы описания исходного сигнала со вновь собранным из микроволновых элементов (рис. 3) также показывает их хорошее совпадение. Наибольшее отличие заметно лишь на невокализованном участке речевого сигнала в самой левой части осциллограммы, а на тональных участках речевого сигнала исходный и синтетический сигналы почти не отличаются друг от друга. И это несмотря на высокую степень естественной нестационарности речевого сигнала на показанном участке.
Рис. 3. Фрагменты осциллограмм сигналов, представленных на рис. 1 и 2 (вверху – исходный оригинальный сигнал, внизу – искусственный, собранный из отдельных микроволновых элементов)
Эксперимент 2. Проверка корректности вычисления и вычитания мощной гармонической помехи. Для проведения этого эксперимента в исходный сигнал была подмешана мощная частотно-модулированная помеха. Сонофильм полученного сигнала показан на рис. 4. Уровень мощности помехи был слабее самого мощного участка исходного речевого сигнала на 5 дБ. На слух речевой сигнал был вполне разборчив несмотря на присутствие сильно мешающей помехи.
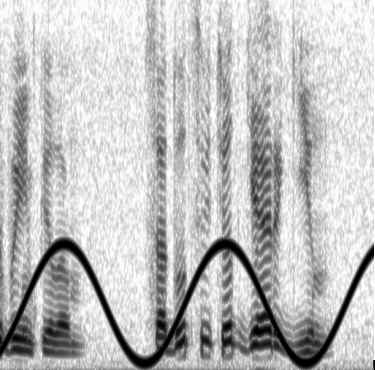
Рис. 4. Сонофильм исходного речевого сигнала с подмешанной к нему мощной частотно-модулированной помехой
В ходе эксперимента эксперт отметил на сонофильме небольшой участок следов помехи, которые автоматически были разложены на микроволновые элементы (1) и вычтены из исследуемого сигнала.
Результат этого эксперимента показан на рис. 5, где хорошо видно, что алгоритм расчета микроволновых элементов и их удаления сработал предельно корректно. Это отразилось в чистоте сонофильма нового обработанного сигнала. В том месте, где находилась помеха, ее следы практически не видны.
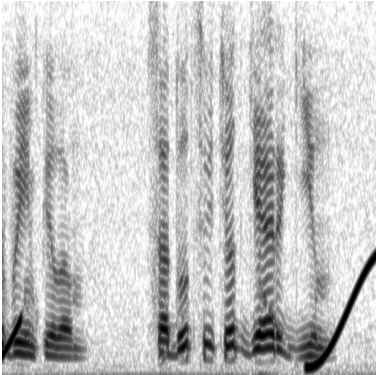
Рис. 5. Сонофильм результата удаления собранной из отдельных микроволновых элементов следов помехи, отраженной на сонофильме на рис. 4
Важно подчеркнуть, что в этом эксперименте сам речевой сигнал не подвергался разложению всех следов на микроволновые элементы и последующей сборке нового сигнала. Речевой сигнал остался полностью аутентичным (равным первоначальному). На микроволновые элементы были разложены только следы помех, которые и вычтены из экспериментального сигнала.
Результаты этого эксперимента хорошо иллюстрируют различие технологий очистки следов в фоноскопии и дактилоскопии. В фоноскопии, убрав микроволновые элементы мощной помехи, можно под ними увидеть (и, значит, услышать) следы полезного сигнала в первозданном (аутентичном) виде. Это принципиально возможно в силу аддитивности акустических сигналов. Поэтому вполне можно извлечение речевого сигнала из под ряда мощных гармонических помех, полностью его заглушающих. Для проверки этого утверждения был проведен следующий эксперимент.
Эксперимент 3. Извлечение речевого сигнала из смеси частотно-модулированных помех, превышающих самые мощные участки речевого сигнала более чем на 20 дБ.
К чистому речевому сигналу были подмешаны мощные частотно-модулированные помехи, из-за которых следы речи стали вообще не слышны. На рис. 6 показаны уровень мощности исходного сигнала (верхняя часть рисунка) и соответствующий фрагмент сонофильма (нижняя часть рисунка). На малом участке экспериментального сигнала эксперт выделил следы помех. Эти следы были автоматически разложены на микроволновые элементы и вычтены из исследуемого сигнала. В результате получен новый сигнал, уровень мощности и сонофильм которого показаны на рис. 7.
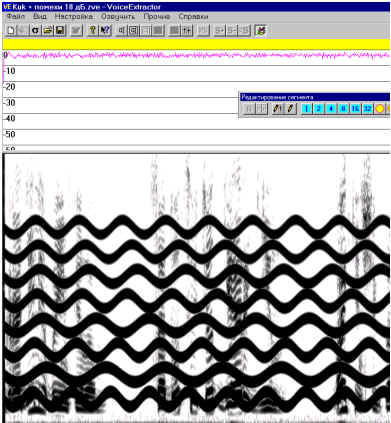
Рис. 6. Сонофильм исходного речевого сигнала с подмешанными к нему мощными частотно- модулированными помехами, из-за чего следы речи вообще не слышны
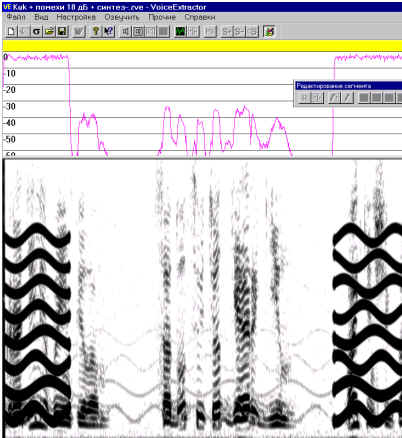
Рис. 7. Сонофильм результата удаления собранных из отдельных микроволновых элементов всех следов помех, отраженных на сонофильме на рис. 6
Отметим следующие важные результаты эксперимента. Во-первых, звучание восстановленного фрагмента речевого сигнала после его усиления имеет весьма удовлетворительно качество. Во-вторых, на обработанном участке сигнала уровень помех снизился примерно на 60 дБ. Контур уровня мощности извлеченного сигнала (на рис.7 вверху) мало отличается от исходного (на рис. 1 вверху). Для того чтобы увидеть все тонкости нового сигнала, пришлось приподнять уровень отрисовки его сонофильма более чем на 20 дБ. В-третьих, сравнение сонофольмов на рис. 6 и 7, показывает, что полностью замаскированные следы речи стали видны в обработанном сигнале. При этом, правда, видны некоторые остатки следов помех.
Следует отметить, что такие результаты могут быть достигнуты лишь в тех случаях, когда следы речевого сигнала реально присутствуют в исследуемом сигнале, а не потеряны в результате клиппирования, сильных нелинейных искажений или когда полезный сигнал слабее помехи настолько, что его в принципе не может зафиксировать аппаратура.
Результаты экспериментов говорят о перспективности предложенной технологии разложения сигналов на микроволновые элементы. Однако на практике могут возникнуть ряд трудностей, среди которых реверберация помещений является одной из самых значительных. Для их выявления был проведен еще один эксперимент.
Эксперимент 4. Извлечение речевого сигнала из совокупности частотно-модулированных помех, делающих речь полностью неразборчивой, при записи их в помещении с неизвестными реверберационными свойствами.
На рис. 8 показаны динамика уровня мощности и сонофильм экспериментальной звукозаписи.
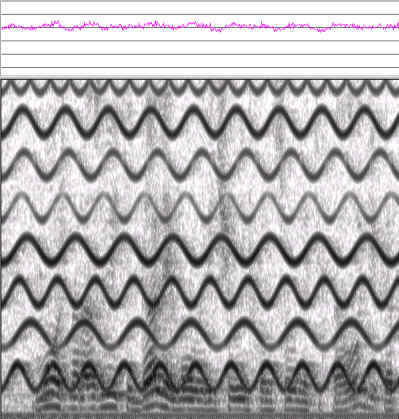
Рис. 8. Сонофильм исходного речевого сигнала с подмешанными к нему мощными частотно модулированными помехами в помещении с неизвестными реверберационными свойствами
Слушая эту экспериментальную фонограмму, можно лишь распознать мужской голос, но нельзя понять ни слова из-за полной маскированности речевого сигнала. Уровень помех превышал самые мощные участки речевого сигнала на 6-10 дБ.
После того, как эксперт отметил на сонофильме следы помех, они были разложены на микроволновые элементы и вычтены из исходного экспериментального сигнала. Результат этой обработки показан на рис. 9.
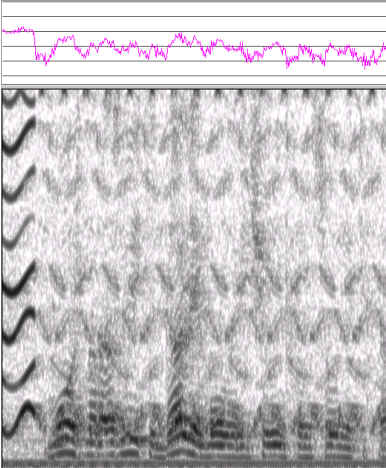
Рис. 9. Сонофильм результата удаления собранных из отдельных микроволновых элементов следов помех, отраженных на сонофильме на рис. 8.
Очищенный таким образом речевой сигнал стал полностью разборчивым, но часть помех осталась. Однако уровень помех не снизился так же значительно, как в эксперименте 3. Он стал лишь на 20 дБ ниже самых мощных участков речевого сигнала (т.е. помехи снизились на 26 – 30 дБ, а не на 60 дБ, как это было в эксперименте 3).
На нижней части рис. 9 видно, что следы помех значительно ослаблены, но не исчезли полностью. Полностью исчезли лишь те следы, которые на смежных кадрах оставались на своих неизменных частотах. Если от кадра к кадру след перемещался по частоте с большой скоростью, то он ослаблялся менее всего. Это объясняется тем, что в действительности в последнем случае в одном кадре присутствуют в непосредственной близости одновременно два следа гармонической помехи. Первый след - основной волны, а второй - отраженной от стен помещения. Поскольку отраженная волна приходит чуть позже прямой, то ее частота всегда будет запаздывать от частоты основной волны на величину, зависящую от скорости модуляции частоты сигнала-помехи. Если внимательно рассмотреть след сигналов помехи на рис. 8, то можно заметить, что помимо основной частотно модулированной помехи радом с ней виднеются смещенные вправо ослабленные следы ее же отраженной волны.
Поскольку в данном эксперименте отраженные волны по амплитуде существенно ниже прямых, то можно утверждать, что в действительности после одного этапа обработки сигнала из него удалились лишь мощные прямые волны, а все отраженные остались без изменения. Исключение составили лишь те участки помех, где они практические не изменялись по частоте. В этом случае и прямая, и отраженные волны полностью удалились одновременно.
Можно повторно пометить следы оставшихся отраженных волн, разложить их на микроволновые элементы и вычесть их из исследуемого сигнала. Но при этом начинают сказываться ограничения на корректность всех подобных операций, поскольку уровень сигнала помехи становится слишком близким к уровню самого речевого сигнала. В таком случае можно по ошибке удалить и следы самого речевого сигнала, в результате чего на сонофильме появятся просто пустые светлые полосы. Но, следует еще раз подчеркнуть, что на всех остальных участках всех кадров сонофильма следы исследуемого речевого сигнала гарантированно остаются аутентичными, что очень важно для криминалистических фоноскопических исследований и экспертиз.
Предложенная технология может применяться при решении широкого класса задач, начиная с реставрации архивных фонограмм с сохранением их аутентичности и заканчивая протоколированием речи, заглушенной мощными помехами.
Статья опубликована на сайте: 12.04.2001