

Что такое вокодер и липредер?
Материалы 2-ой Всероссийской конференции "Теория и практика речевых исследований"
В современных цифровых системах регистрации, передачи и хранения речевой информации с целью уменьшения объема, занимаемого информацией на физических носителях, или скорости ее передачи по цифровым каналам связи применяются различные методы сжатия речи. В таких системах речевой сигнал, преобразованный в цифровой вид, перед записью на носитель или передачей кодируется при помощи специального алгоритма сжатия, а при воспроизведении с носителя или на приеме - декодируется.
Как известно, речевой сигнал в информационно - коммуникативном плане обладает определенной избыточностью, не влияющей на смысловое содержание речевой посылки. При этом сжатие речи возможно за счет частичного удаления этой избыточности, что может не уменьшать разборчивости и качества слухового восприятия речи, но, вместе с тем, лишить ее особых признаков, необходимых для экспертной идентификации речи. Поэтому при производстве экспертизы важно установить как сам факт сжатия, так и его влияние на речевой сигнал.
В настоящее время применяется множество алгоритмов сжатия речи. Все они могут быть реализованы как аппаратнными, так и программными методами. Условно все алгоритмы можно разделить на три вида:
- усовершенствованные виды импульсно-кодовой модуляции (ИКМ, Pulse-Code Modulation PCM);
- вокодеры (от англ. Voice и Coder);
- липредеры (от англ. Linear и Predictor).
Для оценки характера вносимых в речевой сигнал изменений и потерь рассмотрим принципы построения различных методов сжатия.
1. Усовершенствованные виды ИКМ.
Параметры ИКМ при оцифровке речевых сигналов описаны в рекомендациях МККТТ (Международный консультативный комитет по телефонии и телеграфии, CCITT) и, как правило, имеют следующие значения:
- частота дискретизации 8000 Гц;
- число двоичных разрядов на отсчет 8;
- скорость передачи 64000 бит/c.
При этом может быть оцифрован и восстановлен аналоговый сигнал с верхней частотой до 4000 Гц.
При использовании дифференциальной (разностной) ИКМ (ДИКМ, Differencial PCM, DPCM) вместо кодирования отсчетов кодируются разности между соседними отсчетами. Обычно разности отсчетов меньше самих отсчетов. Скорость передачи цифрового потока снижается до 32-56 кбит/c. В системах с логарифмической ДИКМ используют А- и мю законы компандирования для реализации неравномерного квантования. Адаптивная ДИКМ (АДИКМ, Adaptive Differencial PCM, ADPCM) - система ДИКМ с адаптацией квантователя (АЦП и ЦАП) и предсказателя. При АДИКМ оцифровывается не сам сигнал, а его отклонение от предсказанного значения (сигнал ошибки, ошибка предсказания).
Наиболее часто применяются следующие разновидности АДИКМ:
- рекомендация G.721 МККТТ (скорость передачи 32 кбит/с);
- рекомендация G.722 МККТТ (частота дискретизации 16 000 Гц);
- рекомендация G.723 МККТТ (скорость передачи 24 кбит/с);
- Creative ADPCM (4, 2,6 или 2 бита на отсчет);
- IMA/DVI ADPCM (4, 3 или 2 бита на отсчет);
- Microsoft ADPCM.
Рассмотренные выше методы могут вносить незначительные изменения и потери в речевые сигналы (например, сужение динамического диапазона в области высших частот, ограничение крутизны сигнала), которые практически не влияют на аутентичность речи.
Схема вокодера
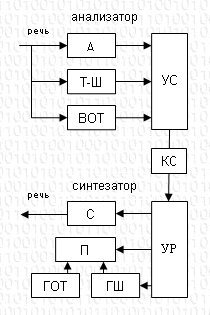 | Анализатор А - анализатор спектра Т-Ш - выделитель сигнала тон-шум ВОТ - выделитель основного тона УО - устройство объедин. сигналов
КС - канал связи
Синтезатор УР - устройство разъед. сигналов С - синтезатор спектра П - переключатель вида спектра ГОТ - генератор основного тона ГШ - генератор шума |
2. Вокодеры.
Вокодеры можно разделить на два класа:
- речеэлементные;
- параметрические.
В речеэлементных вокодерах при кодировании распознаются произносимые элементы речи (например, фонема) и на выход кодера подаются только их номера. В декодере эти элементы создаются по правилам речеобразования или берутся из памяти декодера. Фонемные вокодеры предназначены для получения предельной компрессии речевых сигналов. Область применения фонемных вокодеров - линии командной связи, управление и говорящие автоматы информационно-справочной службы. В таких вокодерах происходит автоматическое распознавание слуховых образов, а не определение параметров речи и, соответственно, теряются все индивидуальные особенности диктора.
Вообще вокодер (от английских слов voice-голос и coder-кодер) представляет собой устройство, которое совершает параметрическое компандирование речевых сигналов.
Компрессия речевых сигналов в кодере осуществляется в анализаторе, который выделяет с речевого сигнала параметры, которые медленно меняются. В декодере при помощи местных источников сигналов, которые управляются принятыми параметрами, синтезируется речевой сигнал.
В параметрических вокодерах с речевого сигнала выделяют два типа параметров и по этим параметрам в декодере синтезируют речь:
- Параметры, которые характеризуют источник речевых колебаний (генераторную функцию) - частота основного тона, ее изменение во времени, моменты появления и исчезновения основного тона (огласованные или гортанные звуки), шумового сигнала (шипящие и свистящие звуки);
- Параметры, которые характеризуют огибающую спектра речевого сигнала.
В декодере, соответственно, по заданным параметрам генерируются основной тон, шум, а затем пропускаются через гребенку полосовых фильтров для восстановления огибающей спектра речевого сигнала.
По принципу определения параметров фильтровой функции различают вокодеры:
- полосные (канальные);
- формантные;
- ортогональне.
В полосных вокодерах спектр речи делится на 7 - 20 полос (каналов) аналоговыми или цифровыми полосовыми фильтрами. Большее число каналов в вокодере дает большую натуральность и разборчивость. С каждого полосового фильтра сигнал поступает на детектор для определения среднего уровня.
В формантных вокодерах огибающая спектра речи описывается комбинацией формант (резонансных частот голосового тракта). Основные параметры формант - центральная частота, амплитуда и ширина спектра.
В ортогональных вокодерах огибающая мгновенного спектра разлагается на составные части в ряд по выбранной системе ортогональных базисных функций. Рассчитанные коэффициенты этого расписания передаются на приемную сторону. Распространение получили гармонические вокодеры, которые используют расписание в ряд Фуръе.
Рассмотренные вокодеры обеспечивают сжатие сигнала до 1200-4800 Бит/с, позволяя восстановить в декодере частоту основного тона с дискретностью в несколько герц и с невысокой точностью огибающую спектра сигнала с периодом изменения 16-40 мс, при этом даже при достаточно высокой разборчивости речи теряются многие индивидуальные особенности диктора.
Из-за сложности определения параметров генераторной функции появились полувокодеры (Voice Excited Vocoder, VEV), в которых вместо сигналов основного тона используется полоса речевого сигнала до 800 - 1000 Гц, которая кодируется, например, АДИКМ, и вместо характеристик основного тона передается на выход кодера. Такой алгоритм позволяет сжать речь до 4800-9600 бит/с, сохраняя генераторную функцию гортани (частоту и закон изменения основного тона) диктора.
3. Липредеры
Одним из наиболее эффективных методов анализа и синтеза речевого сигнала является метод линейного предсказания. Метод получил распространение и продолжает совершенствоваться, суть его в том, что для прогноза текущего отсчета речевого сигнала можно использовать линейно взвешенную сумму предшествующих отсчетов, то есть предсказываемый отсчет
Все методы анализа речи предполагают достаточно медленное изменение свойств речевого сигнала во времени. Характеристики голосового тракта можно считать неизменными на интервале 10-20 мс, то есть параметры надо измерять с частотой порядка 1/20 мс = 50 Гц.
Известно несколько разновидностей метода линейного предсказания, а именно:
- с возбуждением от импульсов основного тона- LPC (Linear Predictive Coding);
- многоимпульсным возбуждением MPELP (Multi Pulse Excidet Linear Predictive) или MPLPC (Multi Pulse Excited LPC);
- возбуждением от остатка предвидения RELP (Residual Excited Linear Predictive);
- возбуждением от кода СELP (Code Excited Linear Predictive).
В кодере LPC сигнал возбуждения передается при помощи трех параметров: периода основного тона (Тот) для звуков, которые вокализованы; сигнала тон-шум (характеризующего наличие в данный момент его параметров или тона, или шума) и амплитуды сигнала.
Кодер с возбуждением от частоты основного тона (ЧОТ) - это кодер LPC, который используется для передачи параметров речевого сигнала со скоростью 2400 бит/с и ниже.
Кодер с возбуждением от ЧОТ не обеспечивает необходимого качества синтезированной речи даже при высокой скорости передачи. Не для всех звуков удается получить точное разделение речи на вокализованную и невокализованную.
Известно, что кроме ЧОТ основого возбуждения, которое имеет место при смыкании голосовой щели, имеется вторичное возбуждение, которое имеется не только при розмыкании голосовой щели, но и при смыкании.
В многоимпульсном возбуждении сигнал остатка LPC представляется в виде последовательности импульсов с неравномерно распределенными интервалами и с различными амплитудами (приблизительно 8 импульсов за 10 мс).
Информация о положениях и амплитудах импульсов возбуждения вместе с LPC-параметрами в каждом кадре формируется кодером.
Если используется скорость до10 параметров LPC 1,8 кбит/с (36 бит кадров20 мс), то при скоростях передачи 16 и 9,6 кбит/с на передачу параметров сигнала возбуждения отводятся скорости соответственно 14,2 и 7,8 кбит/с. На скорости 16 кбит/с и даже ниже создается высококачественная синтезированная речь. При скоростях 16 и 9,6 кбит/с синтезированная речь отвечает по качеству ИКМ сигналам (с логарифмическим компандированием) со скоростями передачи 56 и 52 кбит/с.
На скорости 4,8 кбит/с на прием передаются параметры LPC и кроскореляционная функция. Автокореляционная функция воспроизводится с параметров LPC, которые принимаются, после чего определяются положения и амплитуды импульсов возбуждения. Качество синтезированной речи при многоимпульсном возбуждении при скорости передачи 4,8 кбит/с заметно выше, чем при одноимпульсном возбуждении при той самой скорости передачи.
Кодер с линейным предсказанием, в котором в качестве сигнала возбуждения может использоваться остаток предсказания, называется RELP кодером. Остаток предсказания пропускается через ФНЧ с частотой среза 800 Гц при передаче на скорости 9,6 кбит/с и 600 Гц на скорости 4,8 кбит/с. В первом случае сигнал остатка дискретизируется с частотой 7,2 кбит/с и с той же частотой передается. Остаток 9,6-7,2 = 2,4 кбит/с используются для передачи коэффициентов предсказания и усиления. Во втором случае, т.е. при скорости передачи 4,8 сигнал остатка дискретизируется на частоте 2,4 кбит/с и с этой же скоростью передается. Остаток 2,4 кбит/с используются так же, как и в первом случае.
В декодере сигнал возбуждения восстанавливается во всей полосе частот. При этом верхняя половина возобновленного спектра возбуждения становится зеркальным отображением нижней половины.
Сигнал остатка для RELP-кодера может формироваться и во время декодирования. Дело в том, что для передачи этого сигнала нужна достаточно высокая скорость, являющаяся неприемлемой для кодеров LPC, скорость передачи каких 2,4 кбит/с, поэтому необходимо создавать сигнал остатка на прием сигнала ЧОТ.
Сигнал остатка не обладает амплитудным спектром, а имеет те же самые резонансные области, что и реальный речевой сигнал. Именно поэтому сигнал остатка обладает высокой разборчивостью. Амплитуды формант на выходе синтезирующего фильтра LPC часто бывают меньше амплитуд формант в реальном речевом сигнале. Случается это в результате квантирования параметров LPC.
В линейном предсказателе с возбуждением от кода СELP (Code Excited Linear Predictive) сигнал возбуждения представляется в виде вектора, которому присваивается определенный индекс, т.е. код.
Выбор оптимального вектора осуществляется с большого множества векторов-кандидатов, которые составляют кодовую книгу. Определение размера кодовой книги возбуждения имеет определяющее значение для создания необходимого качества воостановления синтезированного языка.
Метод линейного предсказания с кодовым возбуждением обеспечивает высокое качество речевого сигнала при скоростях передачи 4…16 кбит/с.
По отношению к многоимпульсному методу CELP-метод достигает более высоких показателей восстановления речи при одинаковых скоростях.
В США приняты два федеральных стандарта на применение CELP:
- 1015 (LPC-10E, 2400 бит/с);
- 1016 (E-CELP, 4800 бит/с).
ITU (Международный союз электросвязи, МСЭ) разработал рекомендации:
- G.728 на алгоритм LD-CELP (16 кбит/с);
- G.729 на алгоритм CS-ACELP (8 кбит/с).
Статья опубликована на сайте: 30.11.2006