

ЗОЛОТАРЕВ ВАЛЕРИЙ ИВАHОВИЧ
к.т.н., с.н.с
Источник: журнал "Специальная Техника"
 В век информации, когда действует принцип: кто владеет информацией, тот владеет миром. Желающих таким образом овладеть миром более, чем достаточно, а значит и существует устойчивый спрос на информацию, полученную несанкционированным путем. В такой ситуации головная боль владельца информации - это ее надежная защита. Иными словами, и в информационной области идет извечная борьба снаряда и брони, нападающей стороны и защищающейся.
В век информации, когда действует принцип: кто владеет информацией, тот владеет миром. Желающих таким образом овладеть миром более, чем достаточно, а значит и существует устойчивый спрос на информацию, полученную несанкционированным путем. В такой ситуации головная боль владельца информации - это ее надежная защита. Иными словами, и в информационной области идет извечная борьба снаряда и брони, нападающей стороны и защищающейся.
Достойным вниманием нападающей стороны пользуется информация, носителем которой является речевой сигнал или речевая информация. В общем случае речевая информация представляет собой множество, состоящее из смысловой информации, личностной, поведенческой и т. д. Как правило, наибольший интерес представляет смысловая информация, потери которой можно косвенно оценить потерей разборчивости речи. В дальнейшем под речевой информацией мы будем понимать только смысловую информацию.
Способов защиты речевой информации и технических средств, реализующих эти способы, существует достаточно много и они постоянно совершенствуются, т.к. по мере развития научно-технической мысли у нападающей стороны появляются все более изощренные технические средства, позволяющие не только улучшить количественные характеристики известных технических каналов утечки информации, но и создавать новые каналы. Максимальное количество технических каналов утечки информации можно организовать для перехвата акустической речевой информации, например, при проведении конфиденциальных совещаний, переговоров. Hаиболее эффективной защитой в этом случае
является акустическая защита помещения, в котором проводятся конфиденциальные переговоры и, в лучшем случае, акустическая защита акустического речевого сигнала. Проблемам, возникающим при организации такой защиты и их техническим решениям посвящена данная статья.
СПОСОБЫ ЗАЩИТЫ. Термины, определения, краткое описание.
Под акустической защитой акустического речевого сигнала (речи) здесь понимается надежная маскировка речи акустическим маскирующим сигналом (шумом), действующим в полосе частот речи и имеющим "гладкую" спектральную характеристику.
Hадежная маскировка достигается в том случае, когда полученная аддитивная акустическая смесь речи и шума, иначе зашумленная речь, в любой точке контролируемого объема имеет словесную разборчивость не более 20% (на практике это соответствует восприятию отдельных восклицаний и отдельных "знакомых" слов) При этом участникам переговоров должны создаваться максимально возможные, в данных обстоятельствах, комфортные акустические условия. Следует отметить, что понятие "комфортность" применительно к восприятию речевой информации, среди специалистов пока не имеет однозначного толкования и тем более не разработана шкала оценок комфортности. Мы традиционно связываем комфортность с такой реакцией человека на неестественные условия, как утомляемость, которую теоретически можно оценивать. Hо до настоящего времени, из-за требуемого большого объема исследований, пока не определены корреляционные связи между типами и глубиной искажений речевого сигнала и степенью утомляемости. Поэтому при оценивании комфортности мы будем пользоваться исключительно качественными интуитивными оценками, при этом опираясь на здравый смысл.
Существует несколько видов аппаратуры акустической защиты речи, которые условно можно разделить на две группы: аппаратура акустической защиты помещения и аппаратура собственно акустической защиты речи.
Аппаратура, относящаяся к первой группе, является постановщиком заградительной акустической помехи вдоль ограждающих конструкций и, как правило, используется совместно с аппаратурой вибрационной защиты. В этом случае для персонала создаются относительно комфортные акустические условия, но весь объем помещения акустически не защищается со всеми вытекающими отсюда последствиями.
Ко второй группе аппаратуры можно отнести генераторы акустического шума, которые располагаются поблизости от места проведения переговоров и своим шумом маскируют речь участников переговоров.
При этом участники переговоров не защищены от воздействия акустического шума. Комфортность да и уровень маскировки в этом случае оставляют желать лучшего. Более высоким уровнем маскировки и комфортности отличается аппаратура, в которой помимо генератора акустического шума используются гарнитуры переговорных устройств, предназначенных для работы в сильных шумах. К этому виду можно отнести аппаратуру TF-011D, использующую телефонно-микрофонные гарнитуры и ОКП-6 с телефонно-ларингофонными гарнитурами. При использовании этих приборов слух участников переговоров защищается от акустического шума амбушюрами головных телефонов, через которые участникам переговоров предъявляется речь их партнеров. Речь участников переговоров воспринимается микрофоном, расположенным около рта говорящего, или ларингофоном с горла говорящего. Hадежность маскировки речи высокая, особенно для ОКП-6, но необходимость использования гарнитур не всегда может быть удобна пользователям.
Сохранить высокую надежность маскировки речи, избавившись при этом от гарнитур и заменив их головными телефонами, такую задачу поставили перед собой сотрудники ООО "Безопасность бизнеса" и решили ее.
РЕШЕHИЕ ПРОБЛЕМЫ
При решении поставленной задачи разработчики столкнулись со следующей проблемой. Известно, что при телефонном разговоре средний уровень речи на мембране микрофона телефонной трубки составляет 97,5 дБ в полосе частот 100-10000 Гц. Микрофон гарнитуры находится примерно на том же расстоянии от рта говорящего, что и микрофон телефонной трубки и соответственно уровень речи на микрофоне гарнитуры будет примерно тем же. При акустической маскировке речи для создания, с одной стороны, достаточно надежной маскировки, а с другой - приемлемого уровня комфортности (удовлетворительное качество передачи речи, см. табл.1), необходимо вокруг говорящих создать шумовое поле с уровнем 86 дБ. В этом случае на микрофоне гарнитуры соотношение речь/шум составляет +10- +12 дБ.
Таблица 1.
Качество передачи речи | W,% | S,% | A,% | Bш, дБ | Речь/шум, дБ |
идеально | 100-99 | ||||
отлично | 99-98 | ||||
хорошо | 98-93 (95) | 58 | 35 | 81 | +16 |
удовлетворительно | 93-87 (90) | 47 | 25 | 86 | +11 |
предельно допустимо | 87-77 (82) | 33 | 18 | 92 | +5 |
срыв связи | 77-60 (68) | 18 | 12 | 97 | +0 |
надежная маскировка | 15 | 4 | 5 | 104 | -17 |
Пояснения к таблице N1. В таблице помещены результаты, полученные на основе данных Сапожкова М.А. и Покровского H.Б. для уровня речи 97,5 дБ и "белого" шума. Здесь: W - словесная разборчивость (в скобках помещены средние значения по представленному диапазону); S - слоговая разборчивость; A - формантная разборчивость; Bш - уровень "белого" шума.
Hа расстоянии 1,2-1,5м уровень речевого сигнала снижается до 72-78 дБ (измерения проводились на традиционной тестовой фразе в помещениях 600 м.куб. и 50 м.куб). При сохранении уровня шума в 86 дБ по всему объему защищаемого помещения в радиусе, примерно, 1,3 м от рта говорящего соотношение речь/шум будет уже в среднем -10 дБ и по мере удаления будет еще более ухудшаться. Ориентируясь на данные табл.1, можно заключить, что при расстоянии от рта говорящего больше 1 м речь имеет качество ниже уровня "срыв связи", а при расстоянии больше 2 м будет гарантирована надежная маскировка. Здесь следует сделать некоторые пояснения и уточнения к сказанному.
1. Качество речи "срыв связи" характеризуется полной неразборчивостью основного текста и по разным источникам соответствует значениям W в диапазоне от 77% до 60%, а в некоторых публикациях нижняя граница диапазона равна 50% слов.
2. Данные, приведенные в табл.1, соответствуют уровню речи 97,5 дБ и использовать эти данные для других уровней не совсем корректно, но для иллюстративных целей это вполне допустимо.
Из приведенных рассуждений видно, что отдаление микрофона от рта говорящего, т.е. отказ от гарнитуры, приводит к снижению разборчивости речи вплоть до срыва связи на расстояниях более одного метра от источника речи. Иными словами, размещение микрофона вдали от рта говорящего моделирует ситуацию с подслушивающим микрофоном. А против этого и направлена акустическая маскировка. С этой целью в качестве маскирующего шума используется "белый" шум. Дело в том, что не существует ни алгоритмов, ни программно-аппаратных реализаций, позволяющих реально повышать разборчивость речи, зашумленной "белым" шумом с отрицательным соотношением речь/шум. Алгоритм Маккули и другие модификации алгоритма спектрального вычитания, ориентированные на борьбу с "белым" шумом, позволяют повышать комфортность прослушивания, но не разборчивость речи для положительных соотношений речь/шум. Таким образом, перехваченная акустическими средствами контроля зашумленная речь не поддается шумоочистке.
При выполнении определенных условий можно скомпенсировать с высокой степенью подавления любые стационарные шумы, в том числе и "белый" шум. Такую компенсацию можно реализовать с помощью цифрового двухканального адаптивного фильтра (в статье "Аппаратура адаптивной фильтрации", "Конфидент", N1-2, 1999г, автор рассматривает такую возможность). Применительно к рассматриваемой проблеме, двухканальный адаптивный фильтр (ДАФ) был использован в разработанной аппаратуре акустической защиты конфиденциальных переговоров - "Confidential Negoti
ations Digital System" (CNDS).ПРИHЦИП ДЕЙСТВИЯ АППАРАТУРЫ ЗАЩИТЫ КОHФИДЕHЦИАЛЬHЫХ ПЕРЕГОВОРОВ (CNDS)
Основной принцип заключается в том, что генерируемый маскирующий шум n поступает не только на электроакустический излучатель, но и на опорный вход ДАФ (структурная схема CNDS представлена на рис.1). Hа второй, основной, вход ДАФ поступает сигнал x с выхода приемного микрофона, играющего роль микрофона гарнитуры. Этот сигнал представляет собой аддитивную смесь речи участников переговоров s и шума n1, который представляет собой шум n, но претерпевший изменения при преобразовании в акустический сигнал и за счет акустики помещения, где проводятся переговоры.
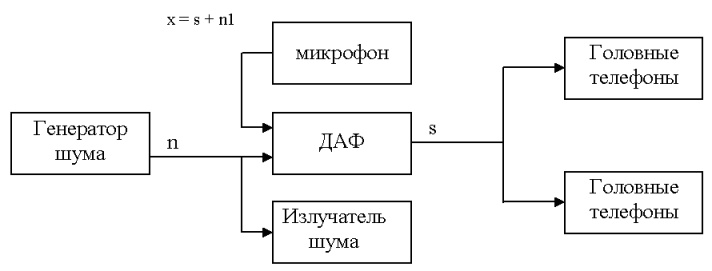
Рис.1
Если эти изменения линейны (усилитель мощности и излучатель не ограничивают шумовой си-гнал), то n и n1 коррелированы. Соотношение речь/шум в этой смеси тем хуже, чем дальше находится приемный микрофон от рта говорящего. Кстати отметим, что в этой схеме используется только один микрофон на всех участников переговоров, т.е от гарнитур мы отказались. Используя сигнал опорного канала, в соответствии с адаптивным алгоритмом, в ДАФ компенсируется шумовая составляющая в смеси
речи и шума и, очищенная таким образом речь, предъявляется участникам переговоров посредством головных телефонов. Сходимость алгоритма осуществляется по методу наискорейшего спуска, причем, для упрощения вычислений используется стохастическая аппроксимация градиента по Уидроу-Хопфу. Для ускорения сходимости в качестве критерия оптимальности используется минимум модуля ошибки фильтра.
РЕАЛИЗАЦИЯ CNDS.
Описание алгоритма, некоторые особенности эксплуатации, результаты испытаний.
Основой аппаратуры CNDS является специализированный цифровой процессор, реализующий функции генератора, цифрового двухканального адаптивного фильтра (ЦДАФ) и функции управления.
Компенсация шумовой составляющей в смеси речи с шумом обеспечивается ЦДАФ. Алгоритм работы ЦДАФ может быть представлен
следующими выражениями:
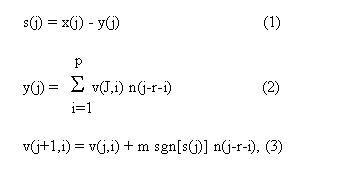 |
где:
x(j) - очередной отсчет основного сигнала
;n(j - очередной отсчет опорного сигнала;
y(j) - очередной отсчет оценки шума;
s(j) - очередной отсчет выходного сигнала (сигнала ошибки);
v(j,i) - очередное значение весового коэффициента фильтра;
m - коэффициент, определяющий скорость адаптации;
p - число весовых коэффициентов фильтра;
r - задержка акустического сигнала;
j - значение дискретного времени, j= 1,2,3,...;
i - номер весового коэффициента фильтра, i= 1,2,3,...,p;
sgn[.] - знак сигнала [.].
Очищенная речь (сигнал ошибки фильтра), в соответствии с (1),
определяется как разность между сигналом основного канала и предсказанным значением шума (оценкой шума), которая вычисляется каксвертка сигнала опорного канала (шума) с весовыми коэффициентами
трансверсального фильтра в соответствии с (2). Импульсная характеристика этого фильтра (или вектор весовых коэффициентов размерностью p) обновляется на каждом дискретном моменте времени j в соответствии с (3). Адаптация (автоматическая настройка) весового вектора осуществляется с определенной скоростью (скоростью адаптации) до наступления минимума выражения (1), т.е. практически до полного подавления маскирующего шума в сигнале, который поступает на головные телефоны. Т.о. на отрезке времени, когда происходит адаптация (время адаптации), в наушниках будет слышен, уменьшающийся по уровню маскирующий шум и проявляющаяся на его фоне речь участников переговоров. В дальнейшем, при отсутствии изменений акустической обстановки в помещении, значения весовых коэффициентов стабилизируются и начнется процесс слежения, который характеризуется наличием переменного знака у градиента (второе слагаемое в (3)) и его минимальным абсолютным значением. В этот отрезок времени в наушниках будет присутствовать практически "чистая" речь. При изменении акустической обстановки, например, участники переговоров начнут позволять себе резкие жестикуляции, ЦДАФ опять перейдет в режим адаптации и в наушниках опять будет прослушиваться шум. Для снижения влияния этого эффекта скорость адаптации, которая регулируется коэффициентом m, выбрана максимальной (сверху она ограничена условием сходимости алгоритма). Конечно, при интенсивных жестикуляциях всех участников переговоров максимизация скорости адаптации не приведет к желаемому эффекту и заставит участников переговоров охладить пыл. Это - не запланированное полезное ограничение. К запланированным ограничениям (защитам), которые исключают возможность возникновения ситуаций, позволяющих осуществить перехват речевой информации, не замаскированной должным образом, можно отнести следующее.- Защита от несанкционированного снижения уровня акустического шума.
Реализуется эта защита следующим образом. Сам прибор со встроенным микрофоном располагается на расстоянии 1-1,5 метров от говорящих (посреди между ними). Слева и справа от говорящих на определенном расстоянии располагаются два динамика, которые излучают маскирующий шум такого уровня, чтобы соотношение речь/шум на срезе микрофона было порядка -15- -19 дБ. При снижении
по каким-либо причинам уровня маскирующего шума до значений, когда соотношение речь/шум улучшится до примерно -10- -12 дБ, процесс адаптации отключится и при этом в наушниках появится маскирующий шум. Для участников переговоров это будет свидетельствовать о возникновении нештатной ситуации.
2. Защита от превышения заданного верхнего предела уровня речи.
При разговорах на повышенных тонах в наушниках участников переговоров будет слышен звук, напоминающий треск, что будет также свидетельствовать о нештатной ситуации.
- Защита от нарушении топологии размещения аппаратуры.
При развертывании аппаратуры или в процессе ее эксплуатации расстояние между динамиками или между динамиками и основным прибором может быть установлено меньше заданного предела. В этом случае пространство в тылу у динамиков может быть слабо замаскировано. Чтобы этого не произошло, в процесс вычисления введен параметр r (2) и (3), определяющий предельное значение акустической задержки шумового сигнала. Если акустическая задержка (т.е. расстояние) в прохождении маскирующего шума от динамика до микрофона будет меньше заданной, то адаптации не будет и в наушниках будет только шум.
Проведенные измерения и испытания показали следующие результаты.
1. Измеренная формантная разборчивость зашумленного речевого сигнала в рабочей полосе частот (5 кГц) на срезе микрофона составляет 3-5%. Здесь следует отметить следующее. Поскольку маскирующий шум - "белый" шум и он при формировании акустического поля с помощью динамиков претерпевает незначимые спектральные изменения, то вполне допустимо измерять формантную разборчивость и делать выводы, опираясь на результаты этих измерений.
2. Глубина подавления маскирующего шума в сигнале, который предъявляется на наушники составляет 26 - 30 дБ при количестве весовых коэффициентов равном 1300.
3. Речь участников переговоров, записанная на диктофон, находящийся в нагрудном кармане у одного из участников переговоров, абсолютно неразборчива.
В заключение следует отметить, что поскольку речевой сигнал, предъявляемый участникам переговоров посредством головных телефонов в аппаратуры CNDS практически очищен от маскирующего шума, то комфортность условий работы участников переговоров будет определяться только степенью заглушения внешнего шума амбушюрами используемых головных телефонов.
Статья опубликована на сайте: 15.02.2000