

Дворянкин Сергей Владимирович, доктор технических наук
Клочкова Екатерина Николаевна
Калужин Роман Владимирович
МАСКИРОВАНИЕ РЕЧЕВЫХ СООБЩЕНИЙ НА ОСНОВЕ СОВРЕМЕННЫХ КОМПЬЮТЕРНЫХ ТЕХНОЛОГИЙ
Источник: журнал "Специальная Техника"
В последние годы защите речевых сообщений конфиденциального характера уделяется все большее внимание. Об этом свидетельствуют многочисленные публикации в специализированных журналах, в том числе и практически в каждом номере журнала “Специальная техника” [1 – 15]. С одной стороны это обусловлено высокой полиинформативностью речевых сообщений. С другой стороны, разнообразием информационных угроз в отношении к акустической (речевой) информации и особенностями сценариев их развития и реализации [1, 2, 5, 13], что нашло свое отражение в большом многообразии современных методов и средств защиты речевых сообщений от несанкционированного доступа.
Различают две основные разновидности нейтрализации утечки акустической (речевой) информации из каналов связи [1, 2, 5, 8]:
- средства физической защиты речевых сообщений, включающие в себя постановщики заградительных помех, блокираторы, фильтры и средства поиска каналов утечки аудиоинформации;
- средства смысловой защиты речевой информации в каналах речевой связи.
Известно, что средства предотвращения утечки аудиоинформации из первой группы обладают рядом слабых мест и ограничений на их использование в той или иной практической ситуации, зависящих от типа линии связи, ее оконечного оборудования, технической квалификации персонала и других факторов [1, 2, 13].
Смысловая защита речевых сообщений посредством криптографических методов до сих пор рассматривалась специалистами как единственная возможность гарантированной или высоконадежной защиты различных каналов речевой связи независимо от условий ведения переговоров, технических характеристик связной аппаратуры и других факторов. Соответствующие устройства речевой защиты, в которых в процессе речепреобразования к участкам и/или параметрам речевого сигнала применяются криптографические алгоритмы (например, алгоритм криптографического преобразования согласно ГОСТ 28147-89) – получили название аналоговых скремблеров и цифровых систем речепреобразования на базе кодеков и вокодеров с последующим шифрованием [2, 8, 12, 14]. Характерной особенностью работы скремблеров является разбиение исходного речевого сигнала (РС) на отдельные участки на частотно-временной сетке с последующим их перемешиванием, суммированием и передачей в канале связи в аналоговой форме. Особенностью же работы устройств цифрового засекречивания речи являются криптографические преобразования над цифровыми данными волновой формы или параметрического описания РС с последующей передачей в канале связи в цифровом виде [2, 8, 12, 14].
Главной целью разработки систем речевой связи является выявление, передача и сохранение тех характеристик речи, которые наиболее важны для восприятия слушателем. Безопасность связи при передаче речевых сообщений, и, прежде всего, направление смысловой защиты РС, основывается на использовании большого количества различных методов и средств преобразования РС. Они меняют характеристики речи таким образом, что она становится неразборчивой или неузнаваемой для подслушивающего лица, перехватившего обработанное речевое сообщение, или вообще скрывается сам факт его передачи.
В последнее время и у разработчиков и потребителей средств смысловой защиты речевых сообщений наблюдается все более устойчивая тенденция к использованию новых компьютерных технологий обеспечения безопасности речевой связи (ОБРС) без использования классических криптографических методов. В этой связи, все большую привлекательность приобретают компьютерные технологии маскирования речевых сообщений, один из видов обобщенной классификации которых представлен на рис. 1. При меньших финансовых затратах на разработку (прежде всего программного обеспечения), распространение и приобретение подобных технологий они могут стать своеобразным буфером между криптографическими системами и системами физической защиты речевых сообщений в каналах связи [5]. Кроме того, при помощи таких технологий удается решать ряд других не менее важных задач ОБРС, чем техническое закрытие РС с целью его защиты от НСД посредством введения неразборчивости. Так, например, можно осуществлять скрытную передачу речевых сообщений в различных каналах связи изменять свой голос для достижения его неузнаваемости при сохранении естественности звучания.
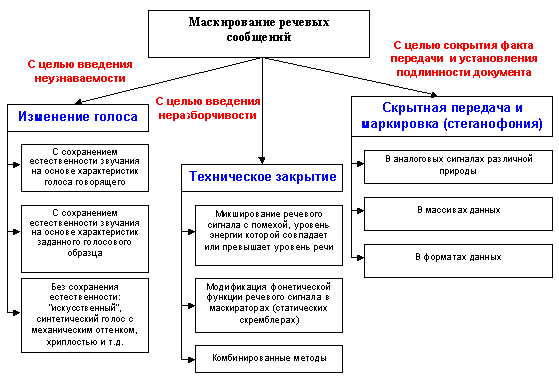
Рис. 1. Общая классификация методов маскирования речевых сообщений
Понятно, что толчок к широкому распространению эти технологии маскирования звуков и речи получили в связи со стремительным развитием в последние годы технических средств мультимедиа и новых подходов к описанию и обработке речевых сигналов. Одним из них является подход к построению специальных программно-аппаратных средств ОБРС, сочетающий идею перевода звукового (речевого) сигнала в вид соответствующих графических образов и обратно из изображения в звук или речь без потери информативности и/или разборчивости с возможностями известных и перспективных методов цифровой обработки изображений. Основным стержнем такого подхода является разработка и применение методов выявления и реконструкции параметров, узкополосных по Гильберту сигналов, присутствующих в этих изображениях. Подобное параметрическое описание сложного исходного акустического (речевого) сигнала позволяет либо полностью воссоздать его звучание, либо восстановить и озвучить "новый" звуковой сигнал по измененным и заданным в таком параметрическом описании свойствам [5, 7].
Исследования показали, что данные, необходимые для расчета параметров элементарных узкополосных сигналов, составляющих исходный звук или речь, могут содержаться в динамических спектральных развертках этого акустического сигнала (АС), а именно, в изображениях корректно рассчитанных амплитудных сонограмм и/или спектрограмм. Такие изображения можно получать в ходе динамического спектрального анализа-синтеза звуков и речи (ДСАС), скользя по исходному сигналу выбранным окном анализа с переходом от взвешенных им выборок к их частотному образу на базе принятого ортогонального базиса. Одним из примеров проведения подобных процедур может служить кратковременный Фурье-анализ-синтез звуковых сигналов. Хотя, в некоторых приложениях ОБРС для проведения ДСАС можно использовать не только гармонический, но и другие базисы, например Вейвлет-функции, кратковременный анализ-синтез Фурье аудио сигналов и речи традиционно применяется чаще.
Параметры узкополосных по Гильберту элементарных звуковых сигналов, составляющих звучание исходного звука или речи, проявляются на изображениях динамических спектрограмм в виде совокупности контуров (линий) перепада яркости или треков (цепочек) локальных и глобальных экстремумов цветовой насыщенности в уровнях одного цвета. С помощью специального программного обеспечения по подобным контурам (трекам), которые и видны на частотно-временной сетке динамических спектрограмм (см. рис. 2, верхняя панель), можно выделить частоты, амплитуды, фазы элементарных звуков сложного акустического (речевого) сигнала, а затем их реконструировать, модифицировать, уничтожать, создавать заново для решения конкретной задачи ОБРС с использованием различных известных методов и инструментов цифровой обработки изображений.

Вверху – естественный женский голос с выделенными траекториями узкополосных составляющих речи;
В центре – искусственный женский голос, синтезированный по заданному образцу;
Внизу – искусственный мужской голос, синтезированный по заданному образцу.
Рис. 2. Сонограммы фразы “Спасибо за кофе. Который час?”
Так, к выделенному участку в центре верхней панели рис. 2 графического образа РС можно применить мощный арсенал средств, предоставляемых известными графическими редакторами типа “Adobe Photoshop”, “Corel Draw”, “Photo Editor” и других. После необходимой обработки данного участка изображения спектрограммы в выбранном графическом редакторе, его можно вставить обратно на свое и другое место для последующего синтеза и прослушивания модифицированного таким образом нового акустического или речевого сигнала.
Заметим, что на изображениях сонограмм (спектрограмм) естественного и искусственных голосов (рис. 2 и последующие), построенных при помощи специализированного программного обеспечения (СПО) "Лазурь", параметр времени откладывается по оси абсцисс, а параметр частоты – по оси ординат, начиная с левого нижнего угла изображения. Максимальная мощность исследуемого сигнала в узле частотно-временной сетки указана черным цветом, минимальная – белым, а промежуточные значения – в градациях серого цвета.
Рассмотрим более подробно различные классы маскирования речевых сообщений, реализуемых при помощи предложенного подхода к обработке РС через обработку их графических образов.
Системы искусственного голоса
Если в традиционных изменителях голоса качеству звучания (естественности и натуральности) искусственной речи не уделялось особого внимания, то сейчас положение меняется. Так, появляются сообщения о программных продуктах, осуществляющих поиск по образцу голоса. Часто при проведении расследований, чтобы не быть узнанными, оперативным работникам приходиться выдавать себя за другое лицо. Все это приводит к возникновению задачи качественного изменения голоса в ходе проведения мероприятий по комплексной защите речевой информации.
Это достаточно сложная задача, поскольку голос у каждого человека индивидуален и узнаваем. Причем слуховое восприятие настолько совершенно, что позволяет опознать самые тонкие оттенки речевого сигнала. Человеческий слух довольно точно определяет признаки искусственности и естественности речи. Поэтому чтобы решить задачу создания компьютерной системы искусственного голоса с сохранением естественности звучания, как на основе голоса говорящего, так и по заданному образцу голоса, необходимо более подробно остановиться на понятии речи и ее основных особенностях.
Под речью обычно понимается некое генерируемое человеком звуковое сообщение, которое может быть объективно зарегистрировано, измерено, сохранено, обработано и, что важно, воспроизведено при помощи приборов и алгоритмов. То есть речевое сообщение может быть представлено в виде некоего речевого сигнала, который в свою очередь может использоваться для обратного воспроизведения речи. То есть можно поставить знак эквивалентности между звуковой речью и ее представлением в виде речевого сигнала, в том числе и в оцифрованном виде, содержащемся в компьютерных файлах.
Известно, что речь представляет собой сложный процесс коммуникации между людьми, включающий в себя как информацию об индивидуальном голосе говорящего, так и информацию о фонетическом качестве. Следовательно, важно обеспечить правильный выбор и обоснование системы признаков, которые определят принцип построения речи. Основные признаки, отвечающие за индивидуальную окраску речи, можно разделить на две группы: связанные с физиологическими механизмами речеобразования и связанные со способами приведения его в действие (артикуляционной деятельностью) [3].
Первая группа признаков основывается на хорошо известной модели речевого тракта, состоящей из передаточной функции резонансной системы и генератора импульсов сигнала возбуждения. Передаточная функция практически полностью характеризует индивидуальную геометрическую форму полостей речевого аппарата. Основными параметрами здесь выступают характеристики четырех формантных областей (средняя частота, частотный диапазон, энергия), огибающая спектра, формантные траектории и производные от этих параметров. Частота импульсов возбуждения находится в прямой зависимости от колебаний голосовых связок, которые, в свою очередь, зависят от длины, толщины и натяжения последних. Основными параметрами здесь являются частота (период) основного тона, параметр тон/шум, звонкость, подъем основного тона и производные от этих параметров [3].
Для расчета параметров, связанных с физиологическими особенностями речевого тракта, наиболее часто используются методы спектрально-временного анализа. Такие методы анализа речевого сигнала адекватны природному механизму восприятия речи. В основе таких методов часто лежит классический Фурье-анализ или параметрический авторегрессионый анализ (линейное предсказание как частный случай). Параметры первой группы достаточно просто выделять из изображений узкополосных динамических сонограмм, на основе предложенного вышеописанного подхода.
Ко второй группе параметров относятся также интонационные характеристики речевого потока, такие как интенсивность, интонации речи, система ударений, ритмическая картина речевой фразы.
Среди параметров речевого сигнала, определяющих индивидуальность голоса человека, необходимо выделить интегральные параметры речи, которые не могут быть отнесены ни к одной из рассмотренных групп, но они сильно коррелированны с ними и формируются под воздействием анатомических особенностей речеобразующего тракта и артикуляционной деятельности человека. То есть анализ интегральных параметров дает возможность определить особенности индивидуального произношения для речевых отрезков различного фонетического содержания [3].
Можно предположить, что, изменяя приведенные характеристики, на основе предложенного подхода к речевой обработке, через обработку графических образов РС, можно найти пути решения поставленной задачи – качественного изменения голоса путем изменения или генерации тех или иных параметров речевого сигнала.
На рынке технических средств защиты речевой информации наиболее распространены устройства, предназначенные для изменения голоса при ведении телефонных переговоров. Как правило, они имеют ступенчатый диапазон изменения голоса: детский, женский, мужской. Так, устройство DTVC II (Южная Корея) имеет двухпозиционный переключатель режима (женский/мужской), четырехпозиционный переключатель степени изменения голоса (низкий/высокий), усилитель звукового диапазона, оперативный выключатель изменителя (при этом разговор не прерывается). Система обратной связи позволяет слушать измененный голос в реальном масштабе времени.
Анализ других существующих недорогих устройств, предназначенных для изменения голоса при ведении телефонных переговоров, показал, что чаще всего в них изменяют частотный диапазон речевого сигнала, реже тембр голоса на низкий или высокий. Полученные таким образом "новые" голоса не обладают в должной мере естественностью и натуральностью звучания, а в ряде случаев имеют металлизированный оттенок, "простуженность" или "хриплость". С другой стороны из-за технической реализации устройств количество степеней изменения голоса ограничено. Кроме того, после непродолжительного временного интервала в процессе телефонных переговоров с применением подобных устройств абоненту становится ясно, что собеседник специально изменил свой голос. У более качественных изменителей голоса имеется другой существенный недостаток – высокая стоимость.
Создание высококачественных изменителей голоса на основе стандартной офисной техники, такой как компьютер, на наш взгляд возможно при реализации предложенного подхода через обработку изображений ее графических образов. Специализированное программное обеспечение подобной компьютерной системы должно модифицировать как гармоническую структуру речевого сигнала, где, как правило, содержатся индивидуальные признаки говорящего, так и фонетическую функцию Пирогова, отвечающую за смысловое содержание речевого сообщения. Такие процедуры уже сейчас можно проводить над изображениями динамических сонограмм с последующим синтезом нового искусственного речевого сигнала по измененному графическому образу. Комбинация таких воздействий при корректно проведенных расчетах вероятно позволит достичь желаемого результата. Некоторые трудности могут возникнуть при модификации паузных участков. Поэтому требует своего решения задача надежного определения тональных и шумовых участков в речевом потоке.
Понятно, что лишь за счет программной реализации на стандартных технических средствах такой изменитель голоса будет не только значительно дешевле, существующих аналогов, но и обеспечит более качественное, действительно натуральное звучание искусственного речевого сигнала. Программное исполнение позволит проводить более плавные изменения голосов от мужского к женскому, от детского к взрослому.
Примером возможностей высококачественного изменителя голоса по заданному образцу является программа "Голосовая мышь", разработанная в Техническом парке МГУ. Особенно хорошие результаты достигаются с ее помощью при переводе текста в речь, озвученную женским голосом. На мужских голосах естественность звучания значительно хуже. В этом можно убедиться при сравнении изображений сонограмм в центральной и нижней панелях (рис. 2) с изображением на верхней панели.
Тем не менее, пока еще рано говорить о работе таких компьютерных систем искусственного голоса в реальном масштабе времени. Вычислительная сложность алгоритмов пока не позволяет реализовать такой режим на компьютерах с процессором классом ниже Pentium-III. Однако проведенные эксперименты показали перспективность и практическую значимость выбранного направления исследований. Некоторые примеры изменения темпа речи и голоса на основе предложенного подхода приведены в [7].
Техническое закрытие речи
Под техническим закрытием речи будем понимать технологии маскирования речи, относящиеся к методам и средствам смысловой защиты речевой информации и имеющие цель обеспечения неразборчивости защищаемого речевого сообщения. Их реализация на практике может быть выражена в микшировании речи шумами и помехами и/или в модификации РС по вычисляемым из его описаний параметрам по заранее известному закону преобразования (закрытия-восстановления).
Распространенным видом технического закрытия речи является микширование исходного РС с помехой с целью передачи в канал связи уже нового неразборчивого на слух звукового сигнала, как правило, лежащего в той же полосе частот, что и исходный. Зная характер изменения и вид помехи, на приемном конце так защищенного канала речевой связи осуществляется нейтрализация ее влияния с дополнительной очисткой и усилением восстановленного речевого сигнала. Так на нижней панели рис. 3 показан результат удаления из полезной смеси квазигармонической помехи, значительно превышающей по уровню энергии интересующий РС, произведенный посредством инструментальных средств СПО “Лазурь”.

Вверху – постановка мощной квазигармонической помехи в речевом сигнале;
Внизу – снятие помехи из полезной смеси на приемном конце канала связи.
Рис. 3. Маскирование речи квазигармонической помехой
Существуют различные виды реализации подобного вида маскирования: когда помеха сравнима по мощности с исходным РС или значительно превышает его, когда помеха является шумовой, квазигармонической или речеподобной и т.п. Подробно вопросы выбора типа помех при построении устройств активной акустической защиты и оценки эффективности защищенности акустической (речевой) информации рассмотрены в [2, 10, 15].
Под модификацией речи будем понимать такое преобразование исходного речевого сигнала, прежде всего его фонетической функции, с целью достижения его неразборчивости и/или неузнаваемости по известному заданному закону, когда параметры этого преобразования на передающем конце канала связи либо известны заранее, либо выделяются из самого исходного сигнала и не изменяются в процессе всего сеанса связи. На приемном конце эти параметры преобразования, либо также известны заранее, либо выделяются из принятого модифицированного сигнала с целью его восстановления неразборчивого РС по тому же заранее известному закону.
Отметим, что на приемном конце не всегда требуется восстановить исходный сигнал в том виде, в каком он был изначально. Например, это касается РС, просинтезированного по графическому образу восстановленного из закрытого изображения сонограммы без учета исходных значений фазовых спектральных составляющих. Тогда волновые формы (осциллограммы) исходного и восстановленного РС будут различны, а их разборчивость и звучание – абсолютно одинаковы. Здесь в полной мере проявляются свойства слухового восприятия человека, которое слабо зависит от фазовых соотношений простейших узкополосных составляющих сложного звукового сигнала. Отсюда вывод: если изображения корректно рассчитанных динамических спектрограмм различных акустических сигналов схожи, то и звучать (восприниматься на слух) они будут одинаковым образом.
Основная задача, которая решается при техническом закрытии речи при помощи описанного подхода – это такое изменение фонетической функции Пирогова исходного РС, при котором модифицированная речь будет абсолютно неразборчива. Эта задача решается посредством динамического изменения огибающей амплитудного спектра РС, то есть в конечном счете через модификацию его формантной структуры. Для оценки конечной разборчивости закрытого и восстановленного РС вполне применимы методики, изложенные в [11].
К числу примеров практической реализации методов такой модификации РС относится простейшая инверсия речи в полосе канала тональной частоты. Более трудоемкая и до этого ранее в практических приложениях не встречавшаяся процедура инверсии циклического сдвига огибающей спектра при сохранении неизменной гармонической структуры исходного РС показана на рис. 4. Известны и более сложные законы взаимообратных преобразований РС с целью достижения его неразборчивости (см. рис. 5).
Также возможна комбинированная реализация методов технического закрытия РС: модификация РС с одновременным наложением помехи. Пример – инверсия спектра плюс квазигармоническая помеха.
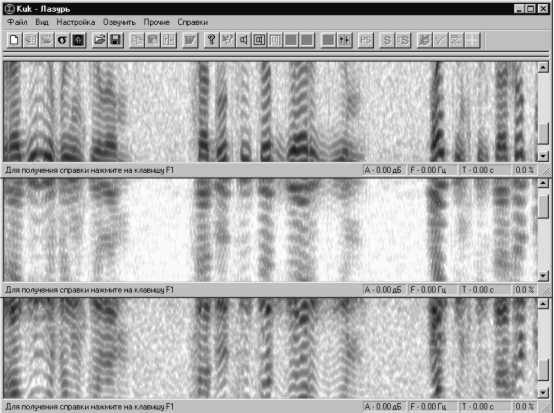
Вверху – сонограмма исходного фрагмента речи;
В центре - сонограмма речевого сигнала с инверсией по спектру;
Внизу – сонограмма речевого сигнала с инверсией и циклическим сдвигом огибающей спектра речи при сохранении ее гармонической структуры.
Рис. 4. Варианты технического закрытия
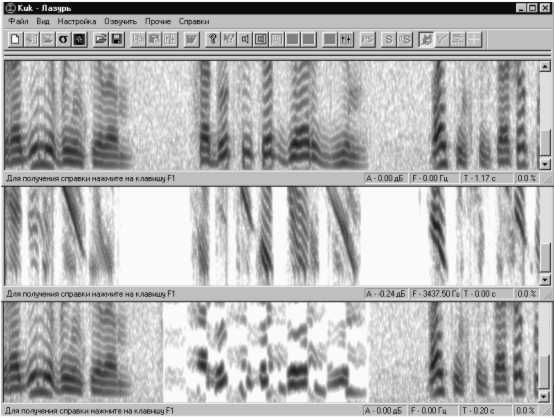
Вверху – сонограмма исходного фрагмента речи;
В центре – сонограмма речевого сигнала с модификацией огибающей спектра посредством ее динамической закрутки;
Внизу – сонограмма центрального фрагмента речевого сигнала, модифицированного “шахматной” частотно-временной функцией.
Рис. 5. Варианты технического закрытия (продолжение)
Следует заметить, что в некоторых публикациях маскираторы речи, типа инверторов спектра и им подобных, относятся к простейшему виду аналоговых статических скремблеров, в которых “ключ” речепреобразования не меняется в процессе всего сеанса, либо в процессе группы сеансов связи. Несмотря на то, что описанные технологии модификации фонетической функции Пирогова и связанной с ней огибающей спектра можно использовать для создания динамических скремблеров, когда ключ преобразования меняется в процессе сеанса от одного часто-временного участка сигнала к другому, тем не менее, на наш взгляд, статические скремблеры все-таки должны быть отнесены к разряду средств технического закрытия и рассматриваться как маскираторы речи. То есть когда говорим о закрытии речевых сообщений, то подразумеваем использование постоянно действующих специфических законов речепреобразования, вносящих неразборчивость в РС и реализованных в маскираторах речи, а когда говорим о засекречивании РС, подразумеваем использование криптографических алгоритмов.
Действительно, существует много споров о разделении методов и средств криптографического засекречивания и технического закрытия речи. Мы полагаем, что технологии технического закрытия РС, основанные на эксплуатации свойств слухового восприятия человека, имеют право на самостоятельное рассмотрение в рамках общей проблемы защиты информации, вне технологий криптографической защиты, и, тем более, не как определенный ее подвид. Здесь уместно провести аналогии с методами и средствами сжатия информации, которые, как известно, хоть и являются в большинстве случаях этапом предварительной обработки криптографического засекречивания данных, тем не менее, во многих приложениях предполагают свое обособленное использование.
Скрытая передача речевых сообщений
В настоящее время меры ОБРС могут быть направлены не только на предотвращение несанкционированного съема защищаемой речевой информации, но и на сокрытие самого факта ее передачи, путем использования для этих целей, стандартных технических средств (СТС), обычных, традиционных протоколов информационного обмена и общедоступных каналов связи (ОКС).
В последние годы такое направление информационной безопасности в компьютерных телекоммуникационных системах, получившее название “стегология” (иногда “стелсология”), активно развивается во всем мире.
Особую популярность в последнее время получила такая часть стегологии как “стеганография”, используемая в области сокрытия конфиденциальной информации в графических изображениях, передаваемых по вычислительным сетям. В тоже время, прогресс, достигнутый в области разработки устройств передачи речевых сообщений, а также в средствах вычислительной техники, открывает новые возможности как для скрытой передачи конфиденциальной информации в аналоговых и цифровых аудио сигналах и речи, так и для скрытой передачи в информационных контейнерах различного рода, на основе использования динамично развивающихся технологий мультимедиа, компьютерной и сотовой телефонии [6]. Такое направление цифровых технологий в области защиты конфиденциальной информации, скрытно присутствующей внутри или поверх открыто передаваемого аудио сигнала, принято сейчас называть "стеганофонией".
В настоящее время широко применяются методы компьютерной стеганофонии, основанные на использовании естественных шумов, которые содержат цифровые массивы, полученные стандартными способами преобразования из аналоговых акустических и видеосигналов. Эти шумы являются ошибками квантования и не могут быть полностью устранены. Использование шумовых бит для передачи дополнительной конфиденциальной информации позволяет создавать скрытый канал передачи данных. В качестве шумовых бит обычно рассматриваются младшие разряды значений отсчетов, которые являются шумом с точки зрения точности измерений и несут наименьшее количество информации, содержащейся в отсчете. Такие биты принято называть наименее значимыми битами (НЗБ) [4,9].
Одним из наиболее распространенных методов стеганофонического сокрытия конфиденциальной информации является метод, основанный на использовании НЗБ звуковых (и/или любых других мультимедийных) данных. В [9] было показано, что подобные естественные потоки НЗБ аудио файлов все-таки не случайны и имеют определенное группирование подряд идущих нулей и единиц, нарушаемое при внедрении дополнительной информации. Были разработаны определенные статистические критерии, предназначенные для обнаружения факта скрытия конфиденциального информационного сообщения в НЗБ аудиосигналов.
Проведенный в работах [4, 9] статистический анализ звуковых данных позволил выявить ряд существенных свойств, оказывающих влияние на обеспечение скрытности конфиденциальных данных и, соответственно, на обеспечение их безопасности подобными методами с использованием шумовых бит. Среди таких свойств необходимо выделить следующие:
- неоднородность последовательностей отсчетов;
- наличие определенных зависимостей между битами в отсчетах;
- наличие определенных зависимостей между самими отсчетами;
- неравновероятность условных распределений в последовательности отсчетов;
- наличие длинных серий одинаковых бит;
- наличие корреляции между НЗБ и старшими битами.
Эти свойства в различной степени наблюдаются в большинстве звуковых файлов и могут быть использованы при построении различных статистических критериев, определяющих факт сокрытия информации в НЗБ. Вот почему подобные методы компьютерной стеганофонии применяются на практике все реже.
Сегодня можно предложить следующие требования к сокрытию конфиденциальной речевой информации (КРИ) и простановке стеганофонических маркеров в сигналах, массивах и форматов данных различной природы:
- восприятие сигналов и данных с заложенной в них КРИ должно быть практически неотличимым от восприятия исходного, “открытого” сообщения, содержащемся в данном сигнале или массиве;
- передаваемые по ОКС конфиденциальные речевые данные, камуфлированные различными сигналами или в неявном виде содержащиеся в их параметрах, не должны легко обнаруживаться в этих сигналах-носителях широко распространенными методами и техническими средствами анализа, имеющимися в наличии в настоящее время;
- в ряде приложений постановка и выявление стеганофонических маркеров не должны зависеть от синхронизации эти процессов и от наличия каких-либо эталонов;
- специальные методы постановки и выявления стеганофонических маркеров должны реализовываться на основе стандартной вычислительной техники или специальных программно-аппаратных средств на ее основе;
- должна обеспечиваться возможность закладки и обнаружения признаков аутентичности в акустический (речевой) сигнал, проявляющихся при незаконном его копировании или модификации независимо от вида представления и передачи этого сигнала (аналогового или цифрового);
- должна обеспечиваться возможность сокрытия КРИ в массивах данных независимо от вида представленной в них информации.
Приведем некоторые примеры использования предложенного подхода обработки звука через обработку его графического образа в задачах компьютерной стеганофонии, подробно описанные в [6].
Так, можно незаметно для слуха передавать и хранить речевой сигнал в другом аудио-, видеосигнале, а также сочетать технологии стеганофонии с технологиями стеганографии, "растворяя" изображения динамических акустических спектрограмм в заданных изображениях – "контейнерах", с последующим их проявлением, синтезом и озвучиванием на приемном конце ОКС.
Изображения сонограмм могут быть использованы для передачи и хранения речи на бумажных носителях в качестве стегомаркеров. При реализации технологий "речевой подписи", связанных с защищаемым документом по смыслу и содержанию примерно также как и электронно-цифровая подпись, на стандартный лист бумаги может быть нанесено от 2 до 4 минут речи телефонного качества звучания в виде разнообразных узорчатых рисунков. В этом случае подлинность документа может быть установлена не только при наличии соответствующих подписей и печатей, но и по информации, содержащейся в “речевой подписи”, отсканировав, просинтезировав и озвучив которую можно услышать ключевые моменты содержания документа, озвученные голосом ответственного лица. Несовпадение озвученных сведений с информацией, содержащейся в документе, говорит о его фальсификации. Подделать же “речевую печать” или “речевую подпись” практически невозможно. Заметим, что такая дешевая технология “речевой подписи” может быть реализована на стандартной офисной технике: компьютер со звуковой картой плюс принтер и сканер.
С помощью предложенного подхода к обработке звуковых сигналов возможно реализовать большое количество самых разнообразных способов компьютерной стеганофонии, эксклюзивных для каждой конкретной задачи скрытной передачи КРИ или маркирования звуками или речью.
Следует отметить, что рассмотренные способы постановки стеганофонических маркеров и скрытой передачи КРИ в большинстве случаев не потребуют синхронизации процессов их введения – выявления или наличия эталонов сравнения, вследствие чего они могут применяться в каналах связи не только при приеме-передаче сигналов и данных, но и в режимах хранения. Поэтому они могут найти применение в аналоговых и цифровых автоответчиках, стандартных системах голосовой почты, компьютерной телефонии и т.п., а также при переносе "стеганофонически" обработанных записей на аудио-, видеокассетах и дискетах.
Если же говорить о передаче конфиденциальной информации в звуках и речи, то проведенные оценки допустимых значений скорости скрытной передачи конфиденциальной информации в аудиосигналах показали, что на сегодняшний день эти значения не превышают 100 бит/с. Пока это максимальные значения, которые могут быть достигнуты при различных способах сокрытия конфиденциальной информации в речевых или акустических сигналах посредством соответствующей обработки графических образов их динамических спектрограмм. Тем не менее, можно предположить, что таких скоростей, скорее всего, будет вполне достаточно для оперативной передачи важных, конфиденциальных сообщений в процессе речевого общения двух абонентов по телефонной линии или посредством приема-передачи аудиокассет, содержащих аудиосигналы – “контейнеры” с информационной закладкой, а также других приложений. Действительно, при таких скоростях в одной минуте речевого сигнала в процессе телефонных переговоров может быть скрытно передано примерно три страницы текста и порядка десяти черно-белых фотоснимков.
Не исключено появление новых способов маскированной передачи конфиденциальной информации в акустических сигналах – “контейнерах” на основе предложенных методов обработки графических образов звука, в результате чего информационная эффективность компьютерных систем скрытной передачи данных может существенно возрасти.
Таким образом, исходя из вышесказанного, можно полагать, что в будущем одним перспективных направлений защиты речевых сообщений в каналах связи и выделенных помещениях, можно считать создание и развитие компьютеризированных систем маскирования речи наряду или при совместном использовании с традиционными технологиями смысловой защиты речевых сообщений, а именно, засекречиванием речевых сигналов на основе криптографических алгоритмов.
Выбор конкретных методов и средств маскирования речи как одного из видов смысловой защиты речевых сообщений, будет зависеть от практических требований, предъявляемых к системе речевой защиты и технических характеристик канала передачи речевой информации.
Литература
- Абалмазов Э.И. Методы и инженерно-технические средства противодействия информационным угрозам//Гротек, 1997, 248 с.
- Абалмазов Э.И. Новая технология защиты телефонных разговоров//Специальная техника, № 1, 1998, с. 4 – 8.
- Агапиев А.Н., Милашенко В.И. Идентификация пользователей вычислительных систем на основе речевых технологий//Конфидент, № 6, 1999, с. 37 –45.
- Барсуков В.С., Романцов А.П. Оценка уровня скрытности мультимедийных стеганографических каналов хранения и передачи информации//Специальная техника, № 6, 1999, с. 52 – 59.
- Дворянкин С.В. Компьютерные технологии защиты речевых сообщений в каналах электросвязи.- М.: МТУСИ, 1999, 52 с.
- Дворянкин С.В. Скрытная передача конфиденциальной информации в аудио сигналах и речи//“БДИ”, №2 (30), 2000, с. 12 – 16.
- Дворянкин С.В. Цифровая обработка изображений динамических спектрограмм аудиосигналов в задачах обеспечения безопасности речевой связи//Специальная техника, № 3, 2000, с. 37 – 45.
- Дворянкин С.В., Девочкин Д.В. Методы закрытия речевых сигналов в телефонных каналах//Защита информации. Конфидент, №5, 1995, с. 45 – 54.
- Дворянкин С.В., Романцов А.П. Статистический метод стеганофонического анализа аудиофайлов.//Тезисы докладов IV межрегионального науч.-техн. семинара "Применение пластиковых карт и защита информации". - М.: МНТОРЭС им. А.С. Попова, 1999, с. 51 – 54.
- Золотарев В.И. Новое решение защиты конфиденциальных переговоров//Специальная техника, № 5, 1999, с. 26 – 30.
- Калинцев Ю.К. Разборчивость речи в цифровых вокодерах. - М.: Радио и связь, 1991, 140 с.
- Кравченко В.Б. Защита речевой информации в каналах связи//Специальная техника, № 4, 1999, с. 2 – 9, № 5, 1999, с. 2 – 11.
- Петраков А.В., Лагутин В.С. Защита абонентского траффика - М.: Радио и связь, 2001, 504 с.
- Сударев И. В. Криптографическая защита телефонных сообщений//Специальная техника, № 2, 1998, с. 47 – 55.
- Хорев А.А., Макаров Ю.К. К оценке эффективности защиты акустической (речевой) информации//Специальная техника, № 5, 2000, с. 46 – 56.
Статья опубликована на сайте: 18.11.2002