

Дворянкин Сергей Владимирович,
кандидат технических наук
Источник: журнал "Специальная Техника"
Введение
По оценкам отечественных и зарубежных специалистов значительная часть передаваемой по общедоступным каналам электросвязи информации приходится на долю речевых сообщений. Такое положение дел определенно сохранится и в будущем, поскольку такому универсальному инструменту человеческого общения как речь, обладающему уникальными признаками эффекта присутствия, эмоциональной окраски, аутентификации, информационной избыточности и другими, присущими только данному коммуникативному (переговорному) процессу, трудно найти какую-либо эквивалентную замену во многих системах связи и передачи информации. Вот почему задачи защиты речевой информации занимают одно из ведущих мест в решении общей проблемы информационной безопасности.
В настоящее время ощущается острая необходимость создания новых специальных программно-аппаратных технических средств и комплексов защиты речевой информации на основе стандартных вычислительных устройств, в которых может быть достигнута значительная экономия временных и материальных ресурсов, затрачиваемых сегодня на разработку традиционных средств специальной техники. Кроме того, может быть увеличен срок использования такого вида новой техники за счет обновления как, прежде всего, программных, так и аппаратных компонентов. Отставание на сегодняшний день наблюдается лишь в общих методах цифровой обработки аудио сигналов, применительно к решению различных задач обеспечения безопасности речевой связи. И здесь как нигде более нужны новые компьютерные технологии получения описаний и обработки речевого сигнала (РС).
Частотно-временные описания аудиосигналов и речи
Как и для большинства других исследований по данной тематике для облегчения понимания последующих выкладок можно ввести определение фонообъекта, под которым здесь и далее будет пониматься реальный объект, генерирующий и излучающий в звуковом диапазоне частот сигналы, которые, будучи преобразованы в цифровую форму, могут записываться и хранится в памяти компьютера в виде отдельных файлов с целью последующей обработки и/или передачи. Также заметим, что под категорию фонообъекта может попадать не только речь человека, но и звуки иной природы, в том числе и различного вида шумы и помехи, которые мешают правильному и качественному слуховому восприятию речевого сигнала, ухудшают или искажают его понимание. Под следами же фонообъекта будем понимать такое его параметрическое описание, которое позволяет либо полностью воссоздать его звучание, либо восстановить и озвучить "новый" аудио сигнал по измененным и заданным в этом параметрическом описании свойствам.
Отметим также, что сложный фонообъект, под которым понимается одновременная совокупность некоторых простейших звуков, можно представить в виде суммы фонообъектов его составляющих. Так вокализованный участок речи с квазигармонической помехой можно представить как суперпозицию помехи и речевого сигнала, который в свою очередь можно рассматривать как совокупность звучания отдельных обертонов, также входящих в состав данного исследуемого звукового фрагмента. В таком примере, все приведенные звуковые слагаемые удобно рассматривать в виде совокупности узкополосных сигналов, имея ввиду, что все спектральные составляющие каждого элементарного звука группируются в относительно узкой по сравнению с некоторой центральной частотой полосе. Впрочем, иногда и сам сложный фонообъект также удобно рассматривать в виде узкополосного процесса.
Из анализа многочисленных публикаций можно сделать вывод, что основными понятиями, которыми приходится оперировать при обсуждении большинства вопросов обеспечения безопасности речевой связи посредством компьютерных технологий, являются понятия разборчивости-неразборчивости речи и тесно связанные с этим понятия выявления, восстановления и реконструкции параметров узкополосных сигналов (следов фонообъектов), совокупность которых и составляет исходный, исследуемый аудио или речевой сигнал (фонообъект). Модификацией, изменением или удалением именно этих параметров можно достичь решения конкретной поставленной задачи. Поэтому разработка и совершенствование компьютерных технологий безопасности речевой связи будет, прежде всего, зависеть от принятых количественных мер оценки узкополосных сигналов, составляющих аудио сигналы и речь, передаваемых - принимаемых в общедоступных каналах связи и/или хранимых на различных материальных носителях.
Исходя из вышесказанного, понятно, что для понимания процессов аудио преобразований, посредством цифровой обработки изображений динамических спектрограмм, желательно выбрать модель аналитического представления звукового сигнала, с которой в дальнейшем было бы удобно работать. В качестве такой модели можно использовать аналитическое описание звукового сигнала в виде суммы узкополосных сигналов по Гильберту.
Результаты исследований последних лет показали, что данные, необходимые для расчета параметров (амплитуд и фаз) следов фонообъектов могут содержаться в динамических спектральных развертках речевого сигнала - амплитудно-фазовых, частотно-временных описаниях мгновенных спектров речи с заданным шагом наблюдения (анализа) по времени и по частоте, - и, прежде всего, в изображениях узкополосных амплитудных сонограмм. Такие развертки, часто называемые матрицами динамических спектральных состояний (МДСС), можно получать в ходе динамического спектрального анализа-синтеза речи (ДСАС), скользя по исходному сигналу выбранным окном анализа с переходом от взвешенных им выборок к их частотному образу на базе принятого ортогонального базиса. Примером такого рода технологий может служить кратковременный Фурье анализ-синтез звуковых сигналов, часто используемый в цифровых системах речепреобразования.
Следы фонообъектов различной природы в виде параметров амплитуд и фаз узкополосных сигналов их составляющих, как будет показано ниже, проявляются на изображениях динамических спектрограмм в виде совокупности контуров (линий) перепада яркости или треков (цепочек) локальных и глобальных экстремумов цветовой насыщенности в уровнях одного цвета. Под обработкой же изображений здесь и далее будем понимать выполнение различных операций над данными, которые носят принципиально двумерный характер и не всегда принимают неотрицательные значения.
В настоящее время существует большое количество хороших программных цифровых анализаторов и редакторов аудио сигналов, предназначенных для визуального анализа звуковых сигналов во временной (осциллограммы, графики уровня мощности сигнала и др.) и, конечно, частотной (сонограммы, кепстры и др.) областях. Среди импортных программных продуктов такого рода следует отметить Cool Edit Pro 1.2, Dart Pro, Sound Forge, Wave Lab, Wave Studio и др., среди отечественных – "SIS 5.2", "Win-Аудио", "Лазурь", Signal Quick Viewer 2 (SQV2), Signal Viewer (SV) и др. В ряде звуковых редакторов имеется возможность производить некоторые виды обработки аудио сигнала, которые можно применить и для решения ограниченного числа задач безопасности РС посредством компьютерных технологий. К этим задачам относится, прежде всего, фильтрация РС и удаление “простых” гармонических, импульсных и шумовых помех в речевом сообщении, принятом из канала связи. Такие несложные виды обработки в большинстве случаях производятся, в основном, во временной области с возможной оценкой полученных результатов обработки в частотной области, исходя из анализа сонограмм. Но только лишь в ряде программных продуктов профессионального исполнения, специально предназначенных для решения наиболее серьезных задач защиты РС, можно производить сложные виды обработки, в том числе и в частотной области, исходя из произведенного анализа изображений динамических сонограмм. Так в новой версии одного такого программного продукта - “Лазурь”, продвигаемым на рынке спецтехники ОАО “Ново”, реализована прямая возможность выборки интересующего участка изображения спектрограммы исследуемого фонообъекта с приложением к нему либо собственных вложенных методов цифровой обработки изображений, либо мощного арсенала средств представляемых известными графическими редакторами типа Adobe Photoshop после транспортировки в них выбранного в "Лазури" участка изображения с возможностью последующей обратной вставки и синтеза таким образом модифицированного графического образа. Все рисунки сонограмм (спектрограмм), приведенные в данной работе, созданы или построены при помощи этого программного продукта. Причем на изображениях сонограмм (спектрограмм) параметр времени откладывается по оси абсцисс, а параметр частоты - по оси ординат, начиная с левого нижнего угла изображения. Максимальная мощность исследуемого сигнала в узле частотно-временной сетки указана черным цветом, минимальная – белым, а промежуточные значения – в уровнях серого цвета.
Основной подход к анализу и обработке аудио сигналов в задачах защиты речевых сообщений
В данной работе автором предложен новый подход к построению специальных программных и программно-аппаратных средств аудио и речепреобразования на основе стандартной вычислительной техники, сочетающий идею перевода звукового сигнала в вид графических образов (изображений спектрограмм и фазограмм) и обратно из изображения в аудио сигнал или речь, без потери информативности или разборчивости, с возможностями известных и перспективных методов и программных продуктов цифровой обработки изображений. Показано, что основным стержнем этого подхода является разработка и применение методов анализа, восстановления, реконструкции и синтеза следов узкополосных сигналов (фонообъектов), составляющих исходный звук и присутствующих на частотно-временной сетке этих изображений. Приведем лишь небольшую толику примеров практической реализации предложенного подхода к анализу-синтезу и обработке аудио сигналов посредством восстановления и реконструкции следов узкополосных звуковых сигналов, составляющих фонообъектов, на представленных изображениях их спектрограмм.
Информационный анализ следов фонообъектов
Очень часто дополнительную информацию, а иногда и главные сведения об исследуемом фонообъекте, можно получить, проводя по соответствующим образом рассчитанным изображениям спектрограмм информационный анализ его следов, или следов фонообъектов, входящих в состав данного аудио сигнала.
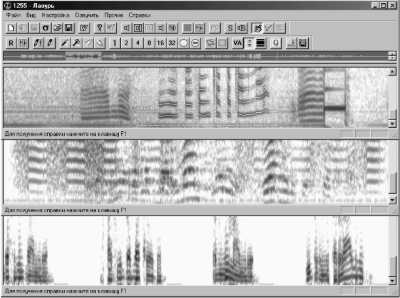
Рис. 1. Следы фонообъектов различной природы, проявляемые на сонограммах
Вверху - следы разговора мужчины и женщины;
В центре - следы акустозаграждающей аппаратуры и речи;
Внизу - пример компьютерного монтажа речи заданным голосом диктора.
Так в верхней панели рис. 1 на узкополосной спектрограмме принятого из канала телефонной связи аудио сигнала представлен фрагмент разговора двух абонентов, одним из которых является мужчина, а другим - женщина. Следы фонообъектов трех типов: обертонов речи мужского и женского голосов на вокализованных не паузных участках сонограммы и вкраплений шумов в паузах - отчетливо видны на представленном изображении верхней панели рис. 1. Траектории (контура) максимальной контрастности или цепочки (треки) локальных максимумов уровней серого и являются теми самыми следами узкополосных составляющих фонообъектов, которые нами и исследуются. Они особенно хорошо заметны на выделенном центральном участке изображения сонограммы рис. 1 в виде светлых линий, проходящих по центру серых и черных полосок одного цвета. Заметим, что сонограмма на этом рисунке, очень похожи на те узкополосные сонограммы, так называемые отпечатки "видимой речи", которые ранее широко использовались для анализа речевых сигналов, и, прежде всего, для идентификации голоса говорящего. Используются подобные сонограммы с "видимой речью" для этих целей и сейчас, но только благодаря описанному подходу к речевой обработке стало возможным по специально рассчитанным и построенным сонограммам, действительно очень похожим на изображения "видимой речи", восстанавливать аудиосигнал прямо сразу по выявленным следам фонообъектов, присутствующим на изображениях этих сонограмм.
Следы голоса мужчины в левой и правой части спектрограммы на верхней панели заметно отличаются от женских (средняя часть спектрограммы) тем, что имеют на вокализованных участках меньшую частоту основного тона, чем женские, т.е. линии гармоник основного тона мужского голоса на этих участках более придвинуты друг к другу, а женские обертона отстоят друг от друга на гораздо большем расстоянии по частоте. Анализируя данную спектрограмму, можно определить временные границы фраз, произнесенных каждым из собеседников, и более успешно провести последующую идентификацию личности по голосу. Некоторые признаки на данной спектрограмме (следы отбоя тлф связи в правой части) свидетельствуют об определенной акустической обстановке вокруг одного из абонентов, из чего можно сделать вывод о том, говорит он из дома или из уличного таксофона.
На средней панели рис. 1 на спектрограмме принятого из акустического канала (воздушная среда) звукового сигнала видны следы “звучания” специальной акустозаграждающей аппаратуры в виде чередующихся столбцов горизонтальных линий, похожих на обертона речи (речеподобная помеха), со столбцами следов мощного шума. Такое быстрое чередование участков разного рода помех предназначено для затруднения работы аппаратуры адаптивной фильтрации РС, в случае если бы она была использована для очистки принятого речевого сообщения от шумов и помех и восстановления его разборчивости. В центре спектрограммы как раз видны следы подавляемого речевого сигнала, утечку которого по акустическому и виброакустическому техническим каналам была призвана предотвратить данная аппаратура защиты речевой информации в помещениях конфиденциальных переговоров. Проанализировав данную спектрограмму, можно сделать определенные выводы о степени соответствия реальной эффективности подавления каналов утечки речевого сигнала, обеспечиваемой данной аппаратурой акустозаграждения, с заявленной на нее в технической документации и принять соответствующие меры либо по повышению, в случае необходимости, степени эффективности подавления конфиденциального РС, либо по возможности восстановления так искаженного речевого сообщения техническими специалистами “нарушителя”, осуществляющих НСД к конфиденциальной речевой информации.
На нижней панели рис. 1 представлена сонограмма искусственной речи, полученной посредством компьютерного монтажа, путем склейки графических образов отдельных фонем, звуков, из предварительно накопленного словаря эталонных фраз “пародируемого” диктора. Несмотря на то, что места склейки достаточно хорошо отретушированы и таким образом синтезированная по новым, измененным графическим образам речь заданного диктора довольно неплохо звучит, тем не менее визуально следы монтажа на данной сонограмме все таки явно заметны. Особенно в концах каждой отдельной новой фразы и в местах склейки участков с разным количеством обертонов.
Сжатие речевых сообщений
Задачи сжатия РС также могут быть решены посредством обработки изображений сонограмм. Схема обработки такова: сначала РС в ходе ДСАС преобразуется в свой графический образ – сонограмму в границах выбранного окна анализа; затем это изображение сонограммы подвергается сжатию по одному из методов сжатия изображений, а коэффициенты сжатия передаются в канал связи; по полученным коэффициентам сжатия на приемном конце канала связи реконструируется изображение исходной сонограммы, по которой затем и производится синтез нового РС. Преимуществом данного способа кодирования речи является то, что используется только одно исходное описание РС – сонограмма со следами фонообъектов, исходя из которого можно получать практически любую необходимую скорость кодирования речи, определяемую пропускной способностью канала связи на данный момент времени, сохраняя при этом максимально возможную разборчивость и качество звучания восстановленной речи. Результаты ряда последних исследований показали, что применяя фрактальные или специальные, основанные на Wavelet преобразованиях, методы сжатия к изображениям сонограмм можно добиться минимальной скорости кодирования 800 бит/с при сохранении словесной разборчивости около 80%.
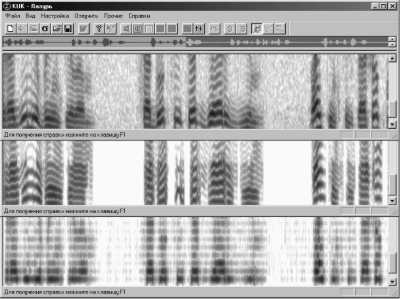
Рис. 2. Примеры сжатия речи
Вверху – сонограмма исходного, исследуемого фрагмента речи;
В центре – сонограмма речевого сигнала, восстановленного после сжатия со скоростью 1000 бит/с, по одному из алгоритмов сжатия изображений исходной сонограммы;
Внизу – сонограмма речевого сигнала, восстановленного после сжатия до 800 бит/с с исключением информации об основном тоне.
Сонограмма исходного участка речи, изображение которой будет использоваться для сжатия методами цифровой обработки изображений и в других приведенных в работе методов речевой обработки, показана в верхней панели рис. 2. Над сонограммой отрисована грубая осциллограмма всего исследуемого РС с указанием на ней места выделенного фрагмента.
Сонограмма того же участка речи, восстановленной после сжатия предложенным способом до скорости 1000 бит/с, и сонограмма все того же участка РС, восстановленного после сжатия до 800 бит/с посредством снятия информации о мелодии основного тона методами цифровой обработки изображений показаны, соответственно, на средней и нижней панелях рис. 2.
Можно видеть, что сонограмма речи, восстановленной после сжатия со скоростью 1000 бит/с более похожа на сонограмму исходного РС, чем сонограмма сигнала, восстановленного после сжатия изображения, полученного посредством выравнивания основного тона. Вот почему первый восстановленный РС и звучит более качественно и натурально, чем второй, при одинаковой их достаточно высокой разборчивости.
Улучшение комфортности восприятия речевых сигналов
Очень часто восприятие речевых сообщений, принятых из каналов связи оставляет желать лучшего только из-за того, что полоса частот РС оказывается смещенной от своего истинного положения. Поместить спектр РС в исходные частотные границы можно, осуществляя прокрутку изображения сонограммы принятой речи на величину необходимого смещения с последующим синтезом нового РС по измененным значениям МДСС.
В некоторых приложениях бывает очень важным осуществлять ускоренное или замедленное прослушивание записанного РС, не изменяя при этом тембра речи. Этого можно достичь, осуществляя необходимое временное масштабирование сонограммы исходной речи, либо растягивая ее по времени либо сжимая, но не выходя при этом за рамки частотной полосы исходного РС. Произведя по полученным измененным сонограммам синтез, в результате получаем речь того же диктора, но воспроизводимую либо в ускоренном, либо в замедленном темпе с сохранением всех признаков, присущих данному говорящему лицу.
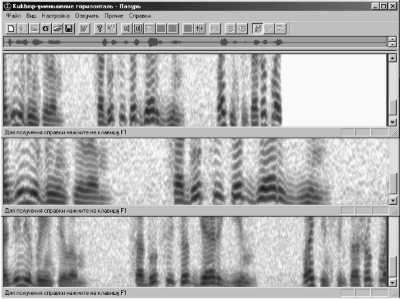
Рис. 3. Изменение темпа и тембра речи
Вверху - сонограмма речи, синтезированной с ускорением темпа на 30% по отношению к сигналу на верхней панели рис. 2;
В центре - сонограмма речи, синтезированной с замедлением темпа на 30% по отношению к сигналу на верхней панели рис. 2;
Внизу - изменение тембра речи посредством уменьшения частотного масштаба исходной сонограммы на верхней панели рис. 2 на 30%.
На рис. 3 вверху и в середине показаны соответственно: сонограмма РС, про синтезированного в первоначальной полосе частот, но со сжатием по времени - в ускоренном на 30% темпе относительного исходной речи в верхней панели рис. 2; сонограмма РС, просинтезированного в первоначальной полосе частот, но с растяжкой по времени - в замедленном на 30% темпе относительно исходной речи в верхней панели рис. 2. В нижней панели рис. 3 представлена сонограмма речевого сигнала, с измененным тембром, просинтезированным без учета фазовых составляющих в ПП "Лазурь" после изменения вертикального, частотного масштаба в Adobe Photoshop , т. е. со сжатием по частоте сонограммы исходного РС примерно на 30%, но с сохранением нормального темпа речи при воспроизведении
Речевые сообщения, сонограммы которых представлены в верхней и средней панелях рис. 3, звучат также естественно и разборчиво, как если бы они были сказаны одним и тем же человеком, но в более быстром или замедленном темпе. Их сонограммы очень напоминают сонограмму фрагмента исходной речи (верхняя панель рис. 2), но воспроизведенную в соответствующем масштабе. При сжатии же изображения спектра речи по частоте (нижняя панель рис. 3) или при его растяжке, приходим к таким же эффектам звучания нового сигнала, которые обычно наблюдаются при озвучивании исходной речи при измененных частотах дискретизации.
Очистка речевых сигналов от шумов и помех
Это наиболее распространенная группа задач в области безопасности РС. Задачи коррекции спектра речи, удаления шумов и помех возникают как в случаях прохождения речевого сигнала по некачественному каналу связи, так и в случаях преднамеренно поставленных помех. В настоящее время на рынке присутствует большое количество различных технических средств, в том числе программно-аппаратных и чисто программных, предназначенных для различных вариантов очистки РС, с помощью которых ряд задач этой группы более или менее успешно решаются. Однако при использовании компьютерных технологий на основе предложенного подхода к обработке речи через обработку изображений ее сонограмм в режиме ДСАС можно добиться наиболее эффективных по затраченным временным и финансовым ресурсам результатов очистки речи в наиболее сложных случаях проявления помех. Это достигается за счет того, что удается добиться определенной гибкости и универсальности в устранении различного рода мешающих разборчивому и качественному слуховому восприятию факторов через выявление, расслоение и устранение следов подобных фонообъектов на изображениях графических образов - спектрограммах или сонограммах всего исходного сигнала.
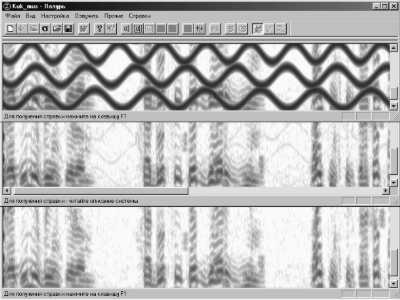
Рис 4. Удаление следов сильной помехи из речевого сигнала
Вверху - сонограмма речи с помехой, значительно превышающей уровень речи;
В центре - сонограмма очищенного участка речи после обработки с использованием квадратичной зависимости нелинейной составляющей полной фазы в упрощенной модели аудио сигнала;
Внизу - сонограмма очищенного участка речи после обработки по уточненной модели речи как совокупности узкополосных сигналов по Гильберту.
Результаты очистки при реализации такого подхода можно контролировать не только на слух, но и визуально через анализ и модификацию изображений сонограмм исходного и восстановленного речевого сигнала на каждом очередном этапе обработки. Таким образом, можно реализовать такие алгоритмы цифровой обработки, которые не удавалось осуществлять ранее. Более того, весь процесс очистки РС от помех можно свести к легко понимаемому пользователем процессу устранения или затирания следов помехи на изображении сонограммы с последующим ретушированием оставшихся следов РС, похожему на редактирование изображений в распространенных графических редакторах.
Наиболее эффективно применение методов цифровой обработки изображений сонограмм в случае необходимости избавления от присутствующих в речевом сигнале стационарных или медленно меняющихся квазигармонических помех. Именно такой пример удаления следов сильной помехи из РС показан на рис. 4.
В верхней панели представлена уже известная по различным публикациям сонограмма с исходным РС с наложенной на него помехой, превышающей речь практически на 25 дБ. Следы помехи отчетливо видны на изображении спектрограммы в виде волнистых жирных черных линий. При воспроизведении такого сигнала будет слышна только одна помеха, а речевого сообщения, любезно предоставленного в виде файла оцифрованных данных автору его ныне здравствующим коллегой и однокурсником Ю. Ромашкиным для подобного рода экспериментов над своим голосом, совсем не будет слышно. Поскольку маскируемая такой мощной помехой речь абсолютно не слышна, и, соответственно, неразборчива, то такой искаженный помехой РС можно также рассматривать и как речевое сообщение, подвергнутое техническому закрытию за счет введения помехи, мешающей его правильному слуховому восприятию.
В средней и нижней панелях рис. 4 представлена сонограмма РС, восстановленного в ходе первоначального выявления и расслоения следов помехи на одном и том же ранее выделенном участке с последующим синтезом и вычитанием просинтезированной помехи из исходной искаженной речи. После такого синтеза на восстановленных участках сонограммы в местах бывших следов помехи хорошо заметны обертона речи, которые она до этого скрывала. Восстановленная таким образом на выделенных участках речь Ю. Ромашкина слышна, понятна и разборчива.
Заметим, однако, что в варианте восстановления, представленном на средней панели рис. 4 использовалась наиболее часто употребляемая исследователями квадратичная зависимость нелинейной составляющей фазы от времени для синтеза помехи, входящей в состав сложного исходного фонообъекта, описанного по упрощенной модели. Поэтому, на восстановленных участках следы помехи, хотя и здорово ослабленной, тем не менее, все еще слабо видны и она еле-еле слышна на фоне разборчивой речи.
Если более корректно производить расчеты фазовой и амплитудной компонент узкополосных составляющих помехи, входящей в состав исходного сигнала, а также функции окна взвешивания в ходе операций ДСАС, то можно достичь и более лучших результатов восстановления искаженной помехой речи. Такой вариант синтеза помехи по ее следам с дальнейшим ее вычитанием из исходного сигнала показан на нижней панели рис. 4, где следы мешающей слуховому восприятию помехи на тех же выделенных участках практически отсутствуют. Естественно, восстановленная таким образом речь, будет звучать еще более натурально.
Еще раз отметим, что используя возможности мощных графических редакторов типа Adobe Photoshop для модификации изображений избранных участков сонограмм искаженных речевых сигналов с последующим синтезом можно добиться еще более впечатляющих результатов по их шумоочистке и восстановлению разборчивости. В этом ключе особенно интересны подходы по одно и двуканальной асинхронной очистке РС при наличии или даже отсутствии опорного сигнала. Также обнадеживают экспериментально проверенные результаты исследований по аналитическому продолжению гармонической структуры речевого сигнала и восстановлению верхних формант на пораженных участках изображений, т.е. в тех местах частотно-временной сетки, где эти параметры были ослаблены, искажены или отсутствовали или из-за плохих условий приема акустического сигнала или из-за неисправности и/или неправильного выбора характеристик используемой аппаратуры звукозаписи. Это тем более интересно, поскольку теоретические основы восстановления матриц искаженных изображений в силу условий их ограниченности в размерах и не отрицательности входящих в них значений уже разработаны математиками.
Компьютерная стеганофония, речевая подпись и техническое закрытие речи
На рис. 5 приведены примеры использования предложенного подхода в задачах компьютерной стеганофонии, являющихся неотъемлемой частью нового бурно развивающего направления защиты информации - компьютерной стеганографии. Так, в верхней панели рис. 5 показана возможность перевода изображений любого содержания в звуковой файл, динамическая спектрограмма которого будет достаточно хорошо визуально совпадать с изображением – прародителем данного звука. В качестве примера показана спектрограмма звука, синтезированного по отсканированному изображению фотоснимка автора данной работы.

Рис. 5. Примеры компьютерной стеганофонии
Вверху – осциллограмма и спектрограмма звукового сигнала, синтезированного по фотоснимку;
Внизу – спектрограмма стеганофонических маркеров в виде надписей печатного и рукописного текста, переведенных в звуковую форму.
Кроме того, можно осуществить и такой способ простановки стеганофонических маркеров, заключающийся в прорисовке условных знаков, текста или надписей поверх или вместо сонограммы исходного аудио сигнала, с последующим синтезом для передачи в общедоступный канал связи. После подобных преобразований получается новый звуковой сигнал, спектрограмма одного из вариантов которого показана на нижней панели рис. 5.
Используя описанные здесь подходы к переводу звука в изображение и обратно, можно предложить новую дополнительную меру защиты конфиденциальных документов от фальсификаций и подделки - "речевую подпись" (РП). Используя такую технологию в конце документа, к примеру договора, наряду с обычной подписью и печатью, каждой из договаривающихся сторон ставится сонограмма с РП, в которой голосом ответственного лица озвучены наиболее важные моменты документа, тесно связанные со смысловым его содержанием - предмет, сумма и сроки действия договора. Изменение этих позиций в документе возможно, но изменить РП уже не удастся. Заметим, что на бумажном листе формата А4 обычным лазерным принтером можно распечатать 2-4 минуты слитной речи телефонного качества.
В качестве экспериментальной проверки этой идеи были озвучены предварительно отсканированные сонограммы из статей в журналах "Спецтехника", "Конфидент" и других печатных и электронных изданий. В результате синтеза по этим сонограммам, полученным при помощи различных программных продуктов, был полностью восстановлен смысл, и даже индивидуальные особенности звучания содержащихся в них речевых сообщений. Причем после прослушивания ряда сонограмм, приводимых в качестве изобразительных примеров реализации некоторых методов шумоочистки в совершенно разных работах, автор с удивлением узнал свой голос.
Понятно, что для представления звуков в виде графических образов в некоторых приложениях можно и нужно применять иные изобразительные представления аудио сигналов. Однако для облегчения понимания применяемых процессов цифровой обработки речи будем опираться на традиционные динамические сонограммы. В этом ключе и рассмотрим приведенные ниже примеры технического закрытия РС.
Один из способов технического закрытия речи, когда РС просто маскируется мощной помехой, уже был рассмотрен нами в рамках обсуждения вопроса очистки искаженного РС от квазигармонических помех. Сонограмма такой звуковой смеси показана на верхней панели рис. 4.
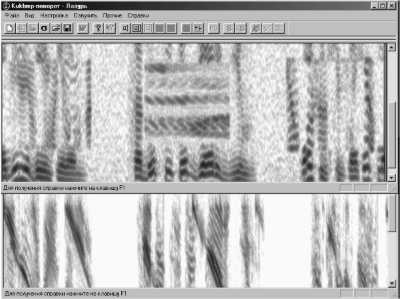
Рис. 6. Примеры технического закрытия речи
Вверху – спектрограмма сигнала, синтезированного по сонограмме в верхней панели рис. 2 с поворотами трех выделенных на ней частотно-временных элементов на 1800 (частотно-временная инверсия), 900 (по часовой стрелке) и 1800 (временная инверсия);
Внизу - спектрограмма варианта технического закрытия речи в виде закручивания в спираль изображения сонограммы в верхней панели рис. 2 с последующим синтезом;
На верхней панели рис. 6 показана сонограмма нового звукового сигнала, полученного на основе синтеза по исходному изображению сонограммы в верхней панели рис. 2, модифицированному путем различных поворотов выделенных частотно-временных элементов. Впервые реализована возможность получить новый звуковой сигнал, спектр которого повернут по отношению к исходному на 900, а не только на 1800 как в случаях частотной и-или временной инверсии.
На нижней панели рис. 6 показан еще один из возможных способов технического закрытия речи, в результате которого получаем речевой сигнал, синтезированный по закрученному в спираль изображению сонограммы исходной речи (верхнея панель рис. 2). Новый РС абсолютно неразборчив и при его озвучивании раздаются звуки, похожие на свист дельфина, из-за циклического перемещения нижних самых мощных гармоник "старого" речевого сигнала по всей полосе частот выбранного канала связи. Восстановить таким образом технически закрытую речь можно, произведя обратное "раскручивание" сонограммы неразборчивой речи.
На основе предложенного подхода возможны и другие варианты решения задач компьютерной стеганофонии, речевой подписи и технического закрытия речи. Следует отметить, что рассмотренные выше способы установки и выявления стеганофонических маркеров и внесения неразборчивости в исходный РС с последующим ее восстановлением не всегда требуют синхронизации процессов обработки, вследствие чего они могут применяться в каналах связи не только при приеме-передаче, но и в режимах хранения РС. Поэтому они могут найти свое применение в широком спектре речепреобразующих и звукообрабатывающих устройств, а также при переносе-хранении обработанных РС на аудиокассетах и дискетах. Понятно, что совместное применение в предложенных методах компьютерной стеганофонии и/ или технического закрытия речи сертифицированных ФАПСИ алгоритмов криптографического закрытия позволит надежно повысить стойкость подобных систем к попыткам нарушителя заполучить защищаемую конфиденциальную речевую информацию.
Заключение
В современных системах безопасности речевой связи компьютерные технологии цифровой обработки сигналов и изображений находят все более широкое применение. Основными требованиями сегодняшнего дня, предъявляемыми к такого рода системам, являются быстрота и эффективность выполнения различных процедур обработки речевого сигнала с использованием стандартных недорогих технических средств компьютерной телефонии, а именно: персонального компьютера, звуковой карты, устройства стыка с телефонной линией и-или модема. Удовлетворить этим требованиям можно, применяя цифровые методы динамического спектрального анализа-синтеза (ДСАС) речевых и аудио сигналов.
Здесь был рассмотрен новый подход к построению специальных программно-аппаратных средств звуко и речепреобразования на основе стандартной вычислительной техники, сочетающий идею перевода звукового сигнала в процессе ДСАС в вид графических образов (изображений спектрограмм и фазограмм) и обратно из изображения в аудиосигнал или речь без потери информативности ли разборчивости с возможностями известных и перспективных методов и программных продуктов цифровой обработки изображений. Было показано, что основным стержнем данного подхода является разработка и использование методов восстановления и реконструкции следов узкополосных составляющих фонообъектов, присутствующих в рассчитанных динамических изображениях спектрограмм и сонограмм.
Приведенные примеры использования предложенного подхода применительно к решению наиболее распространенных задач обеспечения безопасности речевых сообщений показали его высокие потенциальные возможности при осуществлении различных, даже очень сложных и ранее не реализуемых, алгоритмов обработки аудио сигналов, которые уже сегодня применимы для создания компьютерных систем защиты речевых сообщений в общедоступных каналах связи. Данный подход может стать базовым при проектировании новых систем безопасности РС и оценке эффективности использования устройств зашиты речевых сообщений, уже имеющихся на рынке спецтехники.
Статья опубликована на сайте: 16.05.2002